Agent 是一个由 LLM 驱动决策的循环系统(control loop),核心就是这个 loop;最经典的 Agent workflow 可以抽象成 Observe -> Think -> Act -> Observe -> …,LLM 不再只是生成文本,而是决定系统行为。
工业界的标准 Agent Loop 大概长这样:
while not finished:
1. 获取当前状态(context)
2. 让 LLM 决策下一步
3. 执行动作
4. 获取结果
5. 更新状态
展开来说:
用户目标
↓
Planner / Agent
↓
决定下一步 action
↓
调用工具
↓
得到 observation
↓
写入 memory
↓
继续推理
这个循环会不断重复,直到任务完成 / 达到 step limit / 出错或被用户中断。
ReAct
现在几乎所有 Agent 都受 ReAct 思想的影响。ReAct = Reason + Act,核心思想是让 LLM 把思考和行动交替进行。
在 ReAct 之前,LLM 大概有两种模式:纯推理(CoT,但不能真正执行),或者纯行动(直接调工具,但没有推理过程)。ReAct 的贡献是把两者编织在一起,每次 Action 之前必须有 Thought,每次 Observation 之后必须重新 Thought,不断循环 Thought -> Action -> Observation…。
比如,用户询问东京的天气如何:
Thought:
我需要查询天气,调用查询工具
Action:
search_weather("Tokyo")
Observation:
Rainy, 22C
Thought:
已经得到天气结果
Final Answer:
东京今天下雨,22度。
ReAct 可以理解为一种状态机,因为每次 Observation 都会改变状态,然后 Agent 基于这个新的状态重新推理。
这里有一个关键之处是:Agent 的思考过程也是上下文,除了 Observation 之外,Thought 也会喂回模型,这就是为什么 chain-of-thought 有用,因为它在塑造下一步决策。
ReAct 是线性的,每步只走一条路。Tree of Thoughts(ToT)把这个线性过程展开成树:在每个决策点同时探索多个可能的 Thought,用一个评估函数给每条分支打分,选最优的继续深入。
ToT 适合的场景是解答空间需要探索的任务,比如数学证明、代码调试(同一个 bug 可能有多种修法)、创意写作的不同叙事方向,代价是 LLM 调用次数成倍增加,成本很高,通常只在高价值任务上用。
ReAct 也有很多问题,最显著的就是上下文爆炸,前面的所有步骤都在累积,所以才会出现 summarization / 记忆压缩 / scratchpad pruning 等工程补丁;还有,错误 Observation 会污染后续推理,LLM 很容易 hallucinate 工具调用(调不存在的工具、假装执行成功,等等)。
大致上,在 ReAct 思想下,Agent 系统的主要工作就是把 Thought / Action / Observation 组织成稳定的循环,下面分别展开说明这三个阶段。
Thought
Thought 是 Agent 在当前状态下的认知过程,它实际上是在做状态解读 + 决策,大概可以分为下面这些内容:
- 状态理解:LLM 首先要判断现在处于什么位置,上一步的 observation 是成功还是失败?得到的信息是否可信?任务整体进展到哪里了?这一步是规划的前提,很多 intelligence 都来自于对 observation 的正确理解。
- Goal tracking:这是为了防止 LLM 在长任务中漂移,需要经常回顾当前任务是什么、现在是否偏离目标。
- 规划:分解任务,决定 future actions。有些问题不需要调用工具,直接在 Thought 里算出来更高效;有些需要,那么就需要决定调用哪个工具。
- Gap analysis:LLM 会估计自己对某个信息的置信度,进而决定要不要去验证。这是元认知层面的内容,不只是已有的信息,还有「现在还缺什么信息」。置信度高就直接用,置信度低就触发一个查询 Action。
- Self-reflection:当发现前几步的推理有问题时,Thought 会主动否定之前的结论,重新建立推理链。这是最容易出 bug 的地方,LLM 有时会错误地否定正确的推理,或者用同样错误的逻辑修正自己。
- 终止判断:当前信息够不够回答用户的问题?够了就直接输出 Final Answer,不再触发 Action。这个判断如果太保守(总觉得信息不够),Agent 会无限调用工具;太激进(信息不够就急着回答),输出质量就会变差。
Thought 最大的难点是,LLM 并不真正理解世界状态,它只是在当前 context 下做 token prediction,因此 thought quality 高度依赖 context engineering。
还有一个很重要的认知:Thought 其实并不是给人看的解释,而是给下一轮推理看的中间状态,换言之,其主要读者是未来的 LLM 自己;Thought 实际上是 working memory,是 Agent 在 context 里的临时意识流。
规划
最原始的 ReAct 是边走边规划的,局部决策,每一步只考虑下一步。这样的好处是比较灵活,但有短视的问题:容易迷失在细节里,对长任务来说容易偏离原始目标,所以 planning 出现了。
Planning 提供一个长期目标约束,实际上是约束了搜索空间,减少 action space;主流的先规划再执行(Plan-and-Solve)模式就是先让 LLM 生成一份完整的子任务列表,再逐步执行。比如,要求写一份用户分析报告,planner 就会先输出:
1. 扫描项目结构
2. 识别技术栈
3. 阅读核心模块
4. 总结架构
5. 生成报告
这时 Agent 已经做了任务分解,优点是结构清晰,缺点是计划一旦制定就僵化,执行到一半发现计划不对很难回头。
实际工程里常见的是混合模式,用一个 Planner Agent 先拆出高层子任务,再用多个 Executor Agent 各自跑 ReAct 循环完成每个子任务。这个架构的一个好处是 Exector 可以并行运行,而且子任务可以复用。
一个健壮的 planning 模块必须能处理执行中途出现的意外。主要有三个触发重新规划的场景:
- 工具返回错误或空结果时,Thought 需要判断是重试、换工具、还是跳过这个子任务。
- 子任务执行结果和预期偏差很大时(比如搜索到的信息暗示原始假设是错的),需要决定是否要修改后续子任务的目标。
- 循环次数超过上限(比如 20 步),或 LLM 连续两轮输出相同的 Action(陷入死循环)时,需要决定是用目前已有的不完整信息生成一个降级答案,还是报告失败请求人工介入。
- 最难处理的是这一层,因为 LLM 本身不知道自己在死循环,这需要外部的执行框架来强制检测;这也是为什么工程实现上「最大步数」是一个必须设置的参数,不能省略。
真正的 planner 是很难的,因为 LLM 做长期规划并不稳定,它可能会忘记约束、plan 漂移、task decomposition 不合理,或者 hallucinate future,因此很多 Agent 实际上并没有 planning,而是预定义的 workflow + 局部 ReAct,更类似于一个 workflow engine,不是 autonomous planner。
Action
Action 就是把自然语言决策转成可执行操作,这里的核心问题是怎么让 LLM 稳定地产生正确 action,这就是为什么会出现 function calling / tool schema / structured output。
Action 的难点其实非常工程化,这是因为自然语言到精确操作之间,存在巨大的鸿沟。比如,用户要求修一个 bug,这其中可能对应的动作包括不限于:搜代码、跑测试、grep 日志、修改文件、git diff、重启服务……,而 LLM 要选择正确的 action,填入正确参数,控制工具调用的顺序,还要处理失败。主要的一些工程问题包括:
- 工具选择
- 参数生成
- action granularity
- 工具太粗时能做的事情太多,LLM 控制不了;tool 太细时循环次数过多,token 爆炸。
- 权限
- 超时、重试、回滚
因此,Tool design 约等于 API design for LLM,在工程中非常重要。
Action 很危险,因为它有改变现实世界的能力,因此需要合理地约束它。主流的约束方法有:
- 限制 Action Space,不给它危险的 tool,比如禁止 rm、sudo、公网访问
- Human Approval,高风险 action 先请求确认
- Sandbox,让 action 在隔离环境运行
- Verification,执行后验证结果
Function Calling
Function Calling 就是把 action 转成结构化格式,即,在 system prompt 里用结构化的 schema 告诉 LLM 有哪些工具可以用、每个工具做什么、需要什么参数,LLM 按这份 contract 生成调用请求,执行层负责真正运行。
一个典型的工具定义形如:
{
"name": "search_web",
"description": "搜索互联网获取实时信息。当用户需要最新数据、
新闻、或你不确定的事实时使用。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词,越精确越好"
},
"max_results": {
"type": "integer",
"description": "返回结果数量,默认5"
}
},
"required": ["query"]
}
}
此处,description 字段的质量决定了 LLM 调用工具的准确率。LLM 完全靠这段文字来判断什么情况下该用这个工具,如果描述模糊,LLM 就会在不该用的时候用,或者该用的时候不用。好的描述要包含三个要素:工具做什么、什么时候用、什么时候不用。
LLM 要调用这个工具,其输出不再是纯文本,而是一段结构化的请求:
{
"tool_call": {
"name": "search_web",
"arguments": {
"query": "Tesla TSLA 2024年Q4财报",
"max_results": 5
}
}
}
执行层解析这个 JSON,调用真实代码,把结果格式化后追加到对话历史:
Observation: [搜索结果]
1. Tesla Q4 2024 营收 251 亿美元,同比-1%...
2. 毛利率 16.3%,低于预期...
现代的 Function Calling API 都支持 LLM 在一次 Thought 里同时请求调用多个工具,执行层并行运行,所有结果收齐后再进入下一轮推理。
[
{"name": "search_web", "arguments": {"query": "Tesla Q4 2024"}},
{"name": "get_stock_price", "arguments": {"ticker": "TSLA"}},
{"name": "search_web", "arguments": {"query": "Tesla 竞争对手 2024"}}
]
这三个工具并行运行,总耗时是其中最慢的一个,而不是三个之和。对于需要多个独立信息的任务,这能把延迟压缩一半以上。
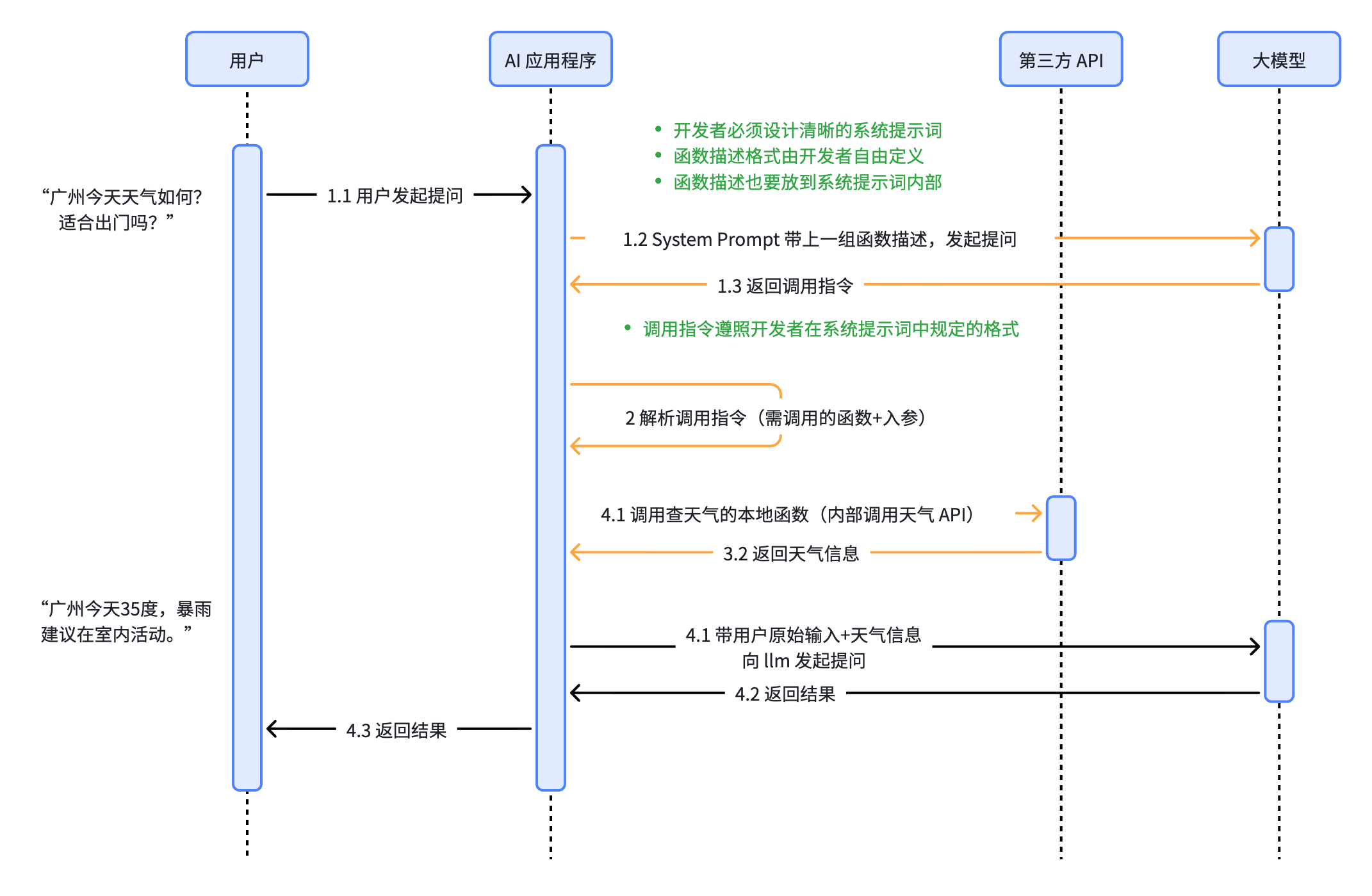
Runtime
工具调用的整个流程是这样的:
- 用户第一次向 LLM 发起提问
- LLM 决定调用工具,输出结构化请求
- Runtime 意识到模型在调用工具,解析调用指令,转而执行对应的程序(类似于操作系统的 syscall),后者返回结果
- Runtime 把结果包装成 observation 再塞回 context,向 LLM 发起第二次提问,这次返回的才是调用工具之后的答案。
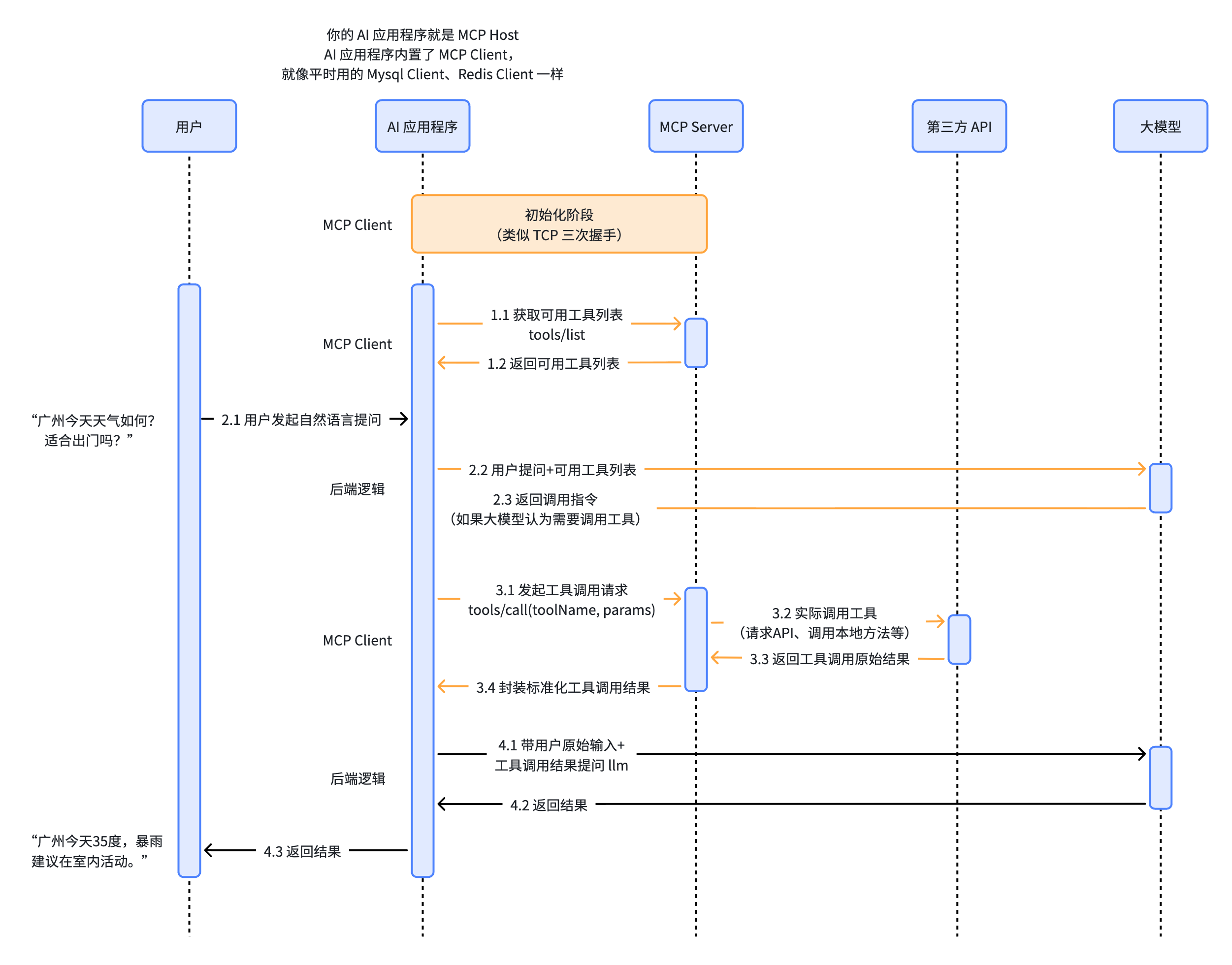
MCP
MCP(Model Context Protocol)是 Anthropic 提出的标准 Tool Calling Interface,解决了不同平台的 Agent 与外部资源通信接口不一致的问题。它是 Runtime 和 Tool 之间的协议层,MCP server 负责暴露工具、描述 schema、执行调用、返回结果,Agent 只需要和 MCP server 交互即可。
Best Practice
Agent 系统中 function calling 的稳定性非常重要,tool interface 设计很大程度上能决定 Agent 能否良好地调用它。实际工程中,主要有以下几种常见问题:
- 工具结果的截断
- 外部 API 可能返回几万字的 HTML 页面,直接塞进上下文会撑爆 token 限制,而且大量无关内容会干扰 LLM 的注意力。需要在执行层做预处理,提取核心字段、截断到合理长度(通常 500-2000 token/个工具结果)。
- 设计错误信息
- 当工具失败时,返回给 LLM 的错误信息应该是可操作的,而不只是堆栈跟踪,比如和
HTTP 429 Too Many Requests比,搜索失败:API 限流,建议换个关键词或稍后重试就对 LLM 的下一步规划有利得多。
- 当工具失败时,返回给 LLM 的错误信息应该是可操作的,而不只是堆栈跟踪,比如和
- 工具选择
- 当工具数量超过 10 个时,LLM 选错工具的概率会上升。常见的缓解方法是把工具分组(先让 LLM 选工具类别,再从该类别里选具体工具),或者用 RAG 动态检索和当前任务最相关的工具子集,而不是把所有工具都塞进 System Prompt。
- 幂等性
- 如果 Agent 在执行途中崩溃重启,某些工具不能被重复调用(比如发送邮件、支付),需要在工具层做去重和幂等保护。
Observation
LLM 不直接感知世界,它只能读取 observation text。Observation 是环境返回给 Agent 的状态信息,相当于 Agent 的感官系统,直接决定了 Thought 质量的上限。
从 LLM 的视角来看,observation 其实就是下一轮 prompt,LLM 只能看到 context token,分不清哪部分是 user input,哪部分是 tool use 结果,哪部分是 thought,因此可以说,observation formatting 就是 prompt engineering。
Observation 最大的工程问题就是如何将其压缩以塞入上下文窗口。常见方法有四种:
- Filtering,只保留关键部分
- Summarization
- Retrieval,比如 RAG
- Ranking,优先高价值的 observation,做 forgetting
这个流程其实很像 cache management。
Multi-agent 的记忆更复杂,因为会出现 shared memory,类似于分布式系统。
记忆
Transformer 本身并没有真正的记忆,它每次推理都要走这个流程:当前输入 tokens → attention → hidden states → next token,所以所谓上下文窗口(context window),实际上就是一次 forward pass 能处理的最大 token 数量,限制来自于计算复杂度和显存(attention 要存 QKV 和 attention matrix)。
Agent 之所以特别依赖上下文窗口,是因为 Agent 做的 plan / tool call / observation / reflection 全部都会塞进 context。Agent 的能力上限,受限于上下文窗口的长度上限。
现在主流的 Agent 记忆系统可以分为长期记忆和短期记忆(即工作记忆),长期记忆又分为情节、语义和程序三种。
工作记忆(Working Memory)
就是当前的上下文窗口:当前任务、历史对话、工具返回结果、System Prompt,LLM 每一步推理都完全基于这个窗口。它精度高,但是 token 很贵,容量有限还易逝,是比较贵重的资源。
工程上最常见的工作记忆管理策略有三种:
- 滑动窗口,只保留最近 N 轮对话,丢弃更早的
- 摘要压缩,把早期对话用 LLM 压缩成一段摘要,摘要代替原文进入上下文
- 选择性注入,不把所有历史都放进去,只把和当前任务相关的部分注入
三种策略各有取舍,复杂系统里通常组合使用。
情节记忆(Episodic Memory)
情节记忆存储的是有时序的事件流:谁在什么时候说了什么、Agent 在哪一步调用了哪个工具、结果是什么,类似于人类的记忆。
情节记忆存储在外部数据库(通常是关系型数据库或文档数据库),每条记录带有时间戳和会话 ID。检索方式是按时序或按会话查找,比如上周用户问过什么、上一个会话里 Agent 执行了哪些操作。
情节记忆让 Agent 能做到两件事:跨会话的连续性(“你上次提到你的项目截止日期是本月底”);以及从历史错误中学习(如果某类任务之前失败过,可以检索出当时的操作轨迹,在新任务里规避同样的路径)。
语义记忆(Semantic Memory)
这是最接近长期知识库的,比如产品文档、公司规章、代码库、行业知识。它和情节记忆的区别在于,情节记忆关心什么时候发生的,语义记忆只关心知识本身是什么。
通常 vector DB + retrieval 属于这一层,实现方式就是 RAG(检索增强生成)的核心:把文档切成小块,用 Embedding 模型转成向量,存进向量数据库(如 Pinecone、Chroma、Weaviate、Milvus)。Agent 需要知识时,把当前问题也转成向量,做相似度搜索,把最相关的 Top-K 块注入上下文。
这里有几个工程细节影响很大:
- 切块策略,按句子、按段落、按语义边界切,结果差异显著
- Top-K 的选择,K 太小可能漏掉关键信息,K 太大会引入噪声干扰 LLM
- 相似度阈值,低于阈值的结果不返回,避免把不相关内容硬塞进上下文
程序记忆(Procedural Memory)
程序记忆类似于一种固化的 skill,是 system prompt 里的工具定义、角色设定、行为约束、输出格式要求。它不在运行时动态检索,而是在 Agent 启动时直接注入。
它定义了 Agent 能做什么、怎么做,是最稳定、最不会改变的记忆层;例如,一个代码审查 Agent 的程序记忆里会有:可以调用哪些代码分析工具、审查时关注哪些维度、输出报告用什么格式,这些在每次会话开始时都完全一致地注入,不依赖任何检索。
在一个实际的 Agent 请求里,四种记忆是这样协同工作的:
- 请求进来,程序记忆(System Prompt + 工具定义)首先进入上下文,确定 Agent 的基本能力边界;
- 然后情节记忆系统检索这个用户的历史会话摘要,注入上下文,让 Agent 知道和这个用户之前聊过什么;
- Thought 阶段判断需要外部知识,触发语义记忆的 RAG 检索,把相关文档块注入;
- 整个推理过程和工具调用结果都在工作记忆(上下文窗口)里实时更新;
- 会话结束后,关键内容从工作记忆写回情节记忆,供下次使用。
这个流程的核心挑战是上下文预算管理,四种记忆同时注入,很容易超出窗口限制。程序记忆通常优先级最高(不能删),情节记忆摘要其次,语义记忆的 RAG 结果和工作记忆的历史对话要相互竞争剩余的空间。Agent 必须决定当前推理最相关的是哪些历史状态,如何分配这个预算,是 Agent 工程里最考验经验的问题之一。
工程落地
什么任务真正适合 Agent?
需要多步操作、中间步骤结果会影响后续决策、人工重复度高。
目前 Agent 落地最好的几个场景:
- Coding Agent,GitHub Copilot 的 Workspace 功能、Cursor 的 Agent 模式都是典型例子,因为分析需求 -> 查找代码 -> 生成修改 -> 运行测试 -> 修复错误这个循环天然适合 Agent。
- Research Agent,即知识型问答和调研,是 RAG Agent 的核心领域,如企业内部知识库问答、竞品分析报告生成、法律文档检索等,这类任务的特点是信息分散在多个来源,需要整合和归纳,但不需要在真实世界做破坏性操作。
- Workflow Agent,比如企业自动化、数据分析流水线,适合结构相对固定的 Agent。
相比之下,不适合 Agent 的任务同样值得明确:需要精确数值计算的任务(LLM 算数不可靠,应该直接调计算工具而不是让 Agent 推理);需要强事务一致性的操作(比如财务系统的多步写入);以及任务边界本身定义不清的情况,如果人类自己都说不清什么算完成,Agent 更不知道什么时候该停止循环。
在具体的框架选型中,Anthropic 的官方 Agent 构建指南建议入门时先不用任何框架,而是试试直接调用 API,手写 ReAct 循环;因为框架封装了很多细节,在不理解那些细节之前,不透明的链路只会让调试更痛苦,等到跑通一个最小可用的 Agent 之后,再根据具体需求选择框架。
在搭建好 Agent 之后,如何评估是很困难的环节,因为 Agent 不是单次输出,而是多步骤带状态的系统,需要评估的是整个行为轨迹。一般来说,从上到下有这么几层评估指标:
- 单步评估,工具选择正确率、参数正确率等,看给定输入,工具调用是否和预期一致。
- 轨迹评估,把 Agent 执行过程中的每一步 Thought + Action + Observation 记录下来,然后判断这条路径走得对不对、效率高不高(步骤数量、冗余操作)。
- 常用方法是 LLM-as-Judge,即用另一个 LLM 来打分,但要注意它有两个系统性偏差:倾向于给较长的回答打高分,以及无法识别事实性幻觉(因为它自己也可能有同样的知识盲区)。
- 端到端评估任务完成率,最接近真实价值,但也最贵,因为需要人工对最终结果打分。
- 实际项目里通常的做法是,用自动化的单步和轨迹评估做高频检测(每次 PR 都跑),用人工评测做低频但高质量的标定(每周或每个版本跑一次),两者结合。
参考文档
- Function calling | OpenAI API
- MCP协议:AI时代的上下文集成革命丨MCP 中文文档
- 近年 AI 应用技术串讲与优质文档分享|Agent、Skill、OpenClaw、Harness……