Summary:
- ACID 四个特性
- 事务隔离级别(读未提交、读已提交、可重复读、串行化)
- 每一层解决了什么问题(脏读、不可重复读、幻读)
- MySQL 默认隔离级别是什么?为什么?
基础概念
事务本质上是数据库操作的一个逻辑单位,可以包含多条 SQL 语句。它的核心特点是要么全部执行成功,要么全部不执行,确保数据不会处于半完成状态;换言之,事务让多步操作对数据库来说看起来像是「一次性完成的操作」。
事务的意义主要体现在几个方面:
- 保证数据一致性:在复杂操作中,避免数据出现逻辑错误或中间状态。比如转账操作:从 A 账户扣钱、给 B 账户加钱,这两步必须同时成功,否则就可能出现资金丢失或重复。
- 隔离并发操作:多个事务同时执行时,数据库能控制它们之间的干扰,保证每个事务的数据读取和修改不会被其他事务破坏。
- 错误恢复:当操作失败或系统崩溃时,事务可以回滚,恢复到操作前的状态,确保数据安全。
事务四大特性(ACID)
- 原子性(Atomicity)
- 事务中的操作要么全部完成,要么全部不做。
- 例子:银行转账操作,如果扣了 A 账户的钱,但加到 B 账户失败,那么整个事务会回滚,A 账户的钱也不会扣。
- 实现方式通常靠日志(Undo/Redo)或者回滚机制。
- 一致性(Consistency)
- 事务执行前后,数据库必须保持逻辑上的正确性。
- 例子:转账前总资金是 1000,事务结束后总资金仍然是 1000。
- 一致性不仅是 ACID 的结果,也依赖数据库约束(主键、外键、唯一性等)来保证。
- 隔离性(Isolation)
- 多个事务并发执行时,每个事务的操作互相独立,互不干扰。
- 数据库通过锁、MVCC 等机制来实现不同隔离级别(Read Uncommitted、Read Committed、Repeatable Read、Serializable)。
- 低隔离级别可能产生脏读、不可重复读、幻读等问题。
- 持久性(Durability)
- 事务一旦提交,对数据库的修改就是永久性的,即使系统崩溃也不会丢失。
- 一般通过写入日志、检查点机制或磁盘持久化保证。
事务隔离级别
SQL 标准定义了四种隔离级别,不同隔离级别允许不同程度的“干扰”。从低到高分别是:
读未提交(Read Uncommitted)
- 一个事务可以读取另一个事务未提交的数据。
- 可能出现脏读(Dirty Read):读到还没提交的数据,之后如果对方回滚,刚才读到的数据就没了 / 过期了
- 并发高,开销小,但是数据不可靠
读已提交(Read Committed)
- 一个事务只能读取已经提交的数据。
- 可以避免脏读,但可能出现 不可重复读(Non-repeatable Read):同一条记录在同一事务中两次读取结果不同,因为另一事务提交了修改
- 这是大多数数据库(Oracle,PostgreSQL)的默认隔离级别
不可重复读的问题在于,虽然每次读到的都是真实的数据,但对于事务来说,它在同一个“逻辑时间点”内看到了两个矛盾的事实。 举例,假设要统计两个银行账户(A 和 B)的总额:
- 初始状态:A 有 500 元,B 有 500 元。总额应为 1000 元。
- 第一步:事务 T1 读取 A 账户,得到 500 元。
- 并发操作:此时另一个事务 T2 将 100 元从 B 转账到 A,并提交。此时 A=600, B=400。
- 第二步:事务 T1 继续读取 B 账户,得到 400 元。
- 结果:事务 T1 计算出的总额是 500 + 400 = 900 元。
在这个例子中,虽然 500 和 400 都是“真实存在过”的数据,但由于它们处于不同的时间切片,导致 T1 统计出了一个现实中从未出现过的总额(900 元)。换言之,不可重复读的问题核心在于,一个事务应该像是在独立运行,不受外界干扰。如果事务内的数据随外部提交而实时波动,事务的隔离性就荡然无存,复杂的业务逻辑(尤其是涉及多步计算和状态流转的场景)将难以编写和维护。
- 可重复读(Repeatable Read)
- 同一个事务中多次读取同一条记录,结果总是一致的。
- 避免了脏读和不可重复读,但可能出现 幻读(Phantom Read):同一条件下查询出的行数在事务中前后不一致,因为另一事务插入或删除了符合条件的行。
- MySQL InnoDB 默认的隔离级别,通过 MVCC 实现
幻读的例子,查询数量 >100 的订单:
- 第一步:事务 T1 查询数量 > 100 的订单,返回 5 行。
- 并发操作:另一个事务 T2 插入了一条数量 = 200 的订单,并提交。
- 第二步:事务 T1 再查一遍,返回 6 行。
幻读破坏的是“范围的一致性”,让事务可能会基于旧数据做决策,这叫「写偏斜」(Write Skew)。举例,业务规则是系统里至少有一个医生在值班:
- 初始状态:数据库里两个医生 A 和 B 都在岗。
- 第一步:事务 T1 读到有两人在岗。
- 并行操作:事务 T2 也读到有两人在岗。
- 第二步:事务 T1 决定让 A 下班。
- 事务 T2 决定让 B 下班。
- 结果:A 和 B 都不在岗,违反了业务规则。
可重复读只能保证前后看到的数据一致,但无法保证基于这个数据做的操作仍然成立。
- 串行化(Serializable)
- 最高隔离级别,事务串行执行。
- 避免脏读、不可重复读和幻读,但性能开销大
- 通常通过加表锁或范围锁实现
总之,对于不同的隔离级别,并行事务时可能发生的现象如下:
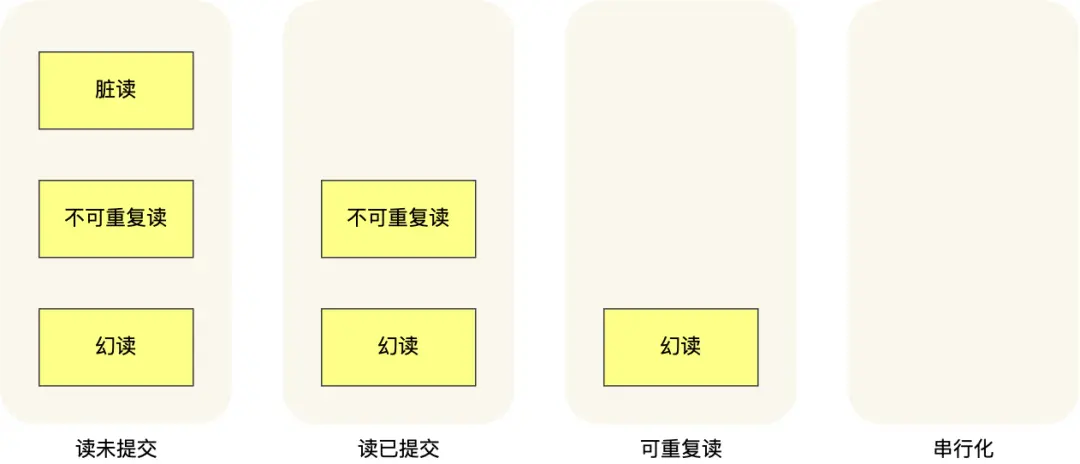
事务实现机制
事务实现 ACID,靠的是日志系统、锁机制和 MVCC。其中,MVCC 的核心是读操作不用加锁,通过读旧版本来实现并发。 简单来说,对不同的隔离级别:
- 读未提交直接读取最新的数据;
- 读已提交在每次读取数据时,都会生成一个新的 Read View;
- 可重复读是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View;
- 串行化通过加读写锁避免并行访问。
后面会单独说明这三者的工作原理,这里就不展开了。