Summary:
- 索引的数据结构(B+树 vs B树、红黑树、Hash),为什么 InnoDB 用 B+树?
- 聚簇索引与二级索引的区别
- 回表、覆盖索引、索引下推
- 联合索引的最左前缀法则
- 索引失效的典型场景
- 如何分析慢查询?
EXPLAIN中type(ALL、index、range、ref、eq_ref、const)的含义 - 查询优化、索引设计原则
基础概念
索引是数据的目录,通过额外维护一份有序的数据映射,加快数据检索的速度。
数据库最朴素的查询方式是全表扫描(full table scan),索引把查询过程从遍历所有数据 O (n) 到快速定位某一小部分数据,一般能到 O (log n)。
在 MySQL(InnoDB)里,索引通常是用 B+树实现的。换言之,数据库会单独维护一棵树,里面存的是:1) 索引列的值(比如 id),2) 指向数据行的位置(或主键)。查询流程变成:先在索引这棵树里查,再根据指针找到真实数据。
索引的数据结构
为什么索引会变快?因为它是有序结构,查找可以使用类似二分/树查找,大幅减少磁盘 I/O 次数。绝大多数关系型数据库(尤其是 MySQL 的 InnoDB 引擎)用的数据结构是 B+ 树。
B+树是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。
以下面的表为例:
CREATE TABLE product (
id int(11) NOT NULL,
product_no varchar(20) DEFAULT NULL,
name varchar(255) DEFAULT NULL,
price decimal(10, 2) DEFAULT NULL,
PRIMARY KEY (id)
);
其主键索引的 B+ 树如图所示:
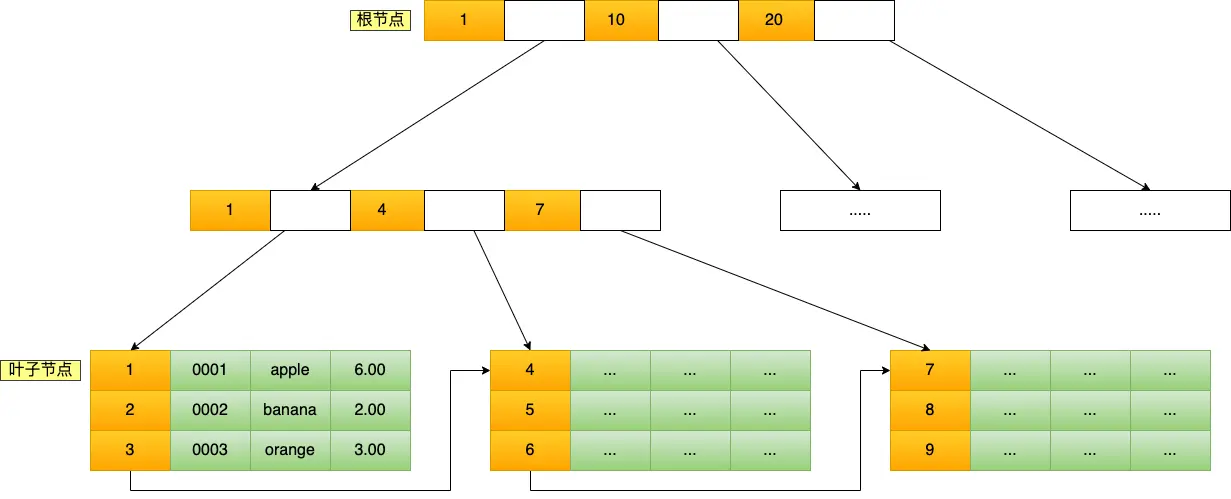
每一层 parent 节点的索引值都会出现在下层 child 的索引值中,因此叶节点中包含了所有索引值信息;叶节点之间形成双向链表(图上画成了单向,实际是双向),这样只要遍历链表就可以做范围查询。
在实际查询中,比如 SELECT * FROM product WHERE id = 5;,B+树会自顶向下逐层查找。B+树的高度很低,即使千万级别的数据,查找的层数(即磁盘 I/O)也不过 3-4 次。
另外,B+树的特点还有:
- B+ 树的节点通常对应磁盘页(比如 16KB),通过节点来减少磁盘读取次数;
- 插入和删除会触发节点分裂和合并,这就是为什么自增主键会比较友好:顺序插入可以减少页分裂。
为什么不用其它数据结构?
- B 树的内部节点也会存数据,而 B+树只有叶节点存数据,因此后者单个节点的数据量更小,在相同的磁盘 I/O 次数下可以查询更多节点;另外,B+树的叶节点形成链表,这样适合在范围查询时顺序扫描。
- 还有,B+树有大量冗余节点,在插入、删除时效率更高,比如删除节点时就不会像 B 树 / 红黑树那样发生复杂的树的变化。
- 红黑树虽然查找是 O(log n),但每个节点只存一个键,树高可能比 B+ 树高很多,磁盘 IO 多,不适合大数据量。
- 哈希索引查询单值很快 O(1),但是不支持范围查询,而且哈希冲突、内存开销大,落盘效率不如 B+ 树。
聚簇索引、二级索引
在创建表时,InnoDB 会自动选择的索引是:
- 主键;
- 如果没有主键,选择第一个不包含 NULL 值的唯一列;
- 如果都没有,就自动生成一个隐式自增 id。
以上的叫作聚簇索引(clustered index),其它的索引都叫二级索引(secondary index)。
二级索引的区别在于,叶节点存放的是主键值,而非整行数据,如下:
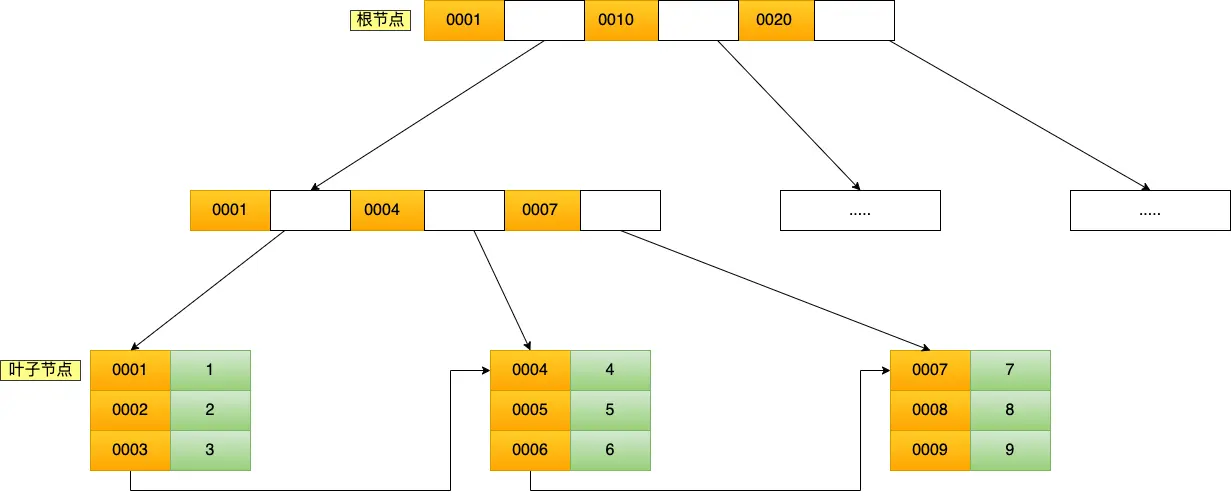
也就是说,使用二级索引查询时,会先通过二级索引 B+树找到主键,然后再到主键 B+树里查到整行数据,这就叫「回表」。但是,如果要查询的数据就在叶节点里(如 SELECT id FROM product WHERE product_no = '0002';),能直接在二级索引 B+树里得到,就不需要再查第二次,这叫「覆盖索引」。
索引类型
MySQL 的常见索引类型有:
- 主键索引(PRIMARY KEY)
- 列值唯一、非空
- 每张表只能有一个主键
- 唯一索引(UNIQUE)
- 列值唯一
- 可以是聚簇索引或二级索引
- 普通索引(INDEX / KEY)
- 既不要求字段是主键,也不要求值 unique
- 查询时可能会回表
- 前缀索引(Prefix Index)
- 对字符串列只索引前 N 个字符,节省空间
- 选择性低时效果差,可能需要回表
- 联合索引(Composite Index)
- 将多个字段组合成一个索引,B+ 树按顺序存储组合键
- 使用最左前缀原则匹配查询条件
- 注意:顺序重要,比如索引 (a,b,c),查询 a 或 a+b 可以用,查询 b+c 不行
联合索引、最左前缀原则
联合索引就是将多个字段组合成一个索引,比如:
CREATE INDEX index_product_no_name ON product(product_no, name);
联合索引 (product_no, name) 的 B+树如下:
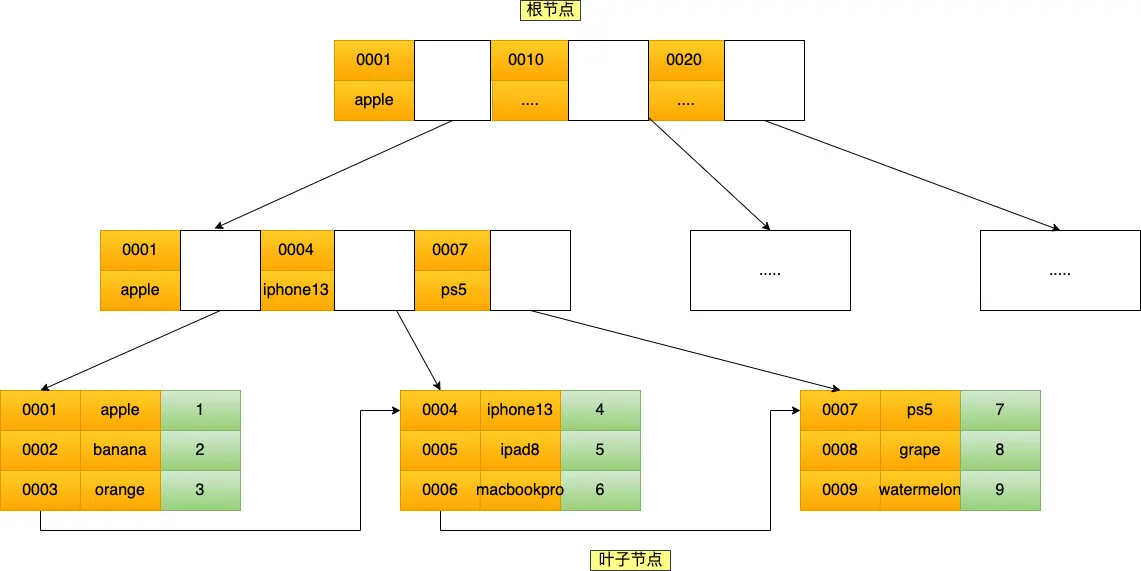
联合索引的 key 值是两个字段按顺序组成的,先按照 product_no 排序,相同的情况再按照 name 排序。因此,查询时也必须从最左的列开始连续匹配。
举例,对于索引 (a,b,c):
WHERE a = ?可以走索引;WHERE a = ? AND b = ?可以走索引;WHERE b = ?不能走索引,因为没有从最左列开始,右边所有的列都是全局无序的;WHERE a = ? AND c = ?可以走索引,b 没有条件会扫描 b 的所有值,但仍然从 a 匹配,所以还能用索引起始部分。
特别注意的是,如果最左列是范围查询(>, <, BETWEEN, LIKE 'xxx%'),索引列后面的列一般就无法再精确匹配,只能扫描范围内的数据。
举例:联合索引 (a, b, c),查询 WHERE a > 5 AND b = 3 时,B+ 树先定位 a > 5 的范围,再顺序扫描 b 列匹配,效率不如前两列精确匹配,但比全表扫描好。
另外,在上面这个查询语句里,尽管 b 列没有使用索引,但可以在联合索引的叶节点就把它的判断条件先应用,筛掉一部分行,也就是只对 b = 3 的行做回表,这样可以减少回表次数,叫「索引下推」。类似地,如果联合索引的列恰好覆盖了所有要查询的数据,也不需要回表。
在建立联合索引时,越靠前的字段越容易被用上,因此要把区分度大的字段放在前面,这样可以快速缩小范围,比如 id;反之,性别这种不同值很少的就没必要放在前面。
索引失效
建立了索引,并不意味着所有时刻都能用上;如果查询语句没法利用 B+ 树的有序结构和快速定位特性,导致索引失效,就会 fallback 到全表扫描,性能极大降低。
常见的索引失效的场景有:
- LIKE 查询不匹配前缀
LIKE 'abc%'可以用索引,因为前缀匹配;LIKE '%abc'或LIKE '%abc%'不能用索引,因为开头不确定,必须扫描全表。
- 对索引列做函数、运算、隐式类型转换
- 查询里对索引列做了函数,比如
WHERE UPPER(name) = 'ALICE',或者WHERE id + 1 = 100,B+ 树的值就没法直接定位,索引失效,需要全表扫描; - 比如
id是整数列,查询条件是WHERE id = '123'(字符串),MySQL 会做类型转换,导致索引失效; - 原因都是改变了列的原始值,B+树用不了。
- 查询里对索引列做了函数,比如
- OR 条件
- 如果 OR 条件有不是索引列的,如
WHERE a = 1 OR b = 2,就会全表扫描。
- 如果 OR 条件有不是索引列的,如
- 最左前缀不匹配
- 对联合索引
(a,b,c)来说,查询必须从最左列开始连续匹配,否则索引失效。
- 对联合索引
!=, NOT IN, < >等负向条件- 这些条件无法利用 B+ 树有序特性,必须扫描全表。
- 数据区分度太低
- 即使符合索引结构,但如果某个值出现在数据行中的百分比太高,一般就会忽略索引,全表扫描,比如性别列。
查询优化、执行计划
EXPLAIN SELECT ... 会展示数据库的执行计划,关键字段包括:
- type:找到数据时使用的扫描方式是什么
- ALL:全表扫描
- index:全索引扫描,和 ALL 的区别是只遍历索引树
- range:范围扫描,用索引范围定位
- 一般来说,查询应该至少达到 range 级别,最好达到 ref
- ref / eq_ref:索引查找
- const / system:结果只有一条的唯一索引,或表只有一条记录
- possible_keys / key:可能用到的,和实际使用的索引
- rows:扫描的行数估算
- extra:额外信息
Using index:覆盖索引,不需要回表;Using where:查询的列没有被索引覆盖;Using temporary:使用临时表保存中间结果,常见于GROUP BY, ORDER BY,这种情况一般要用索引优化;Using filesort:查询语句中包含GROUP BY,而且无法用索引排序,这时不得不使用外部排序,要在内存甚至磁盘里排序,也需要用索引优化。
那么,如何优化查询方法?
- 覆盖索引:让查询字段都在索引里,避免回表;必要时可以建立联合索引
- 不要大表 join,特别是 join 列还没有索引
- 优先驱动小表去扫描大表,可以减少中间结果
- 在大表中避免传统分页,如
SELECT * FROM table ORDER BY id LIMIT 1000000, 20- 因为前面的数据都是不要的,可以内层先在索引层筛选,再回表,类似索引下推:
SELECT * FROM table WHERE id >= (SELECT id FROM table ORDER BY id LIMIT 1000000, 20) - 如果是自增主键,可以用
WHERE id > last_id替代LIMIT offset, count
- 因为前面的数据都是不要的,可以内层先在索引层筛选,再回表,类似索引下推:
- 避免前面说的索引失效场景
索引设计原则
什么字段可以建立索引?
- 有唯一限制,或至少不同值较多的
- 经常用
WHERE查询的,如果查询条件不止一个,可以建立联合索引 - 经常用
GROUP BY和ORDER BY的,因为 B+树里的记录都是有序的
什么字段不建立索引?
- 数据区分度太低的,如性别
- 数据很少的
- 不会作为查询条件的
- 经常更新的,每次修改都需要重建索引,影响性能
建立索引时要注意什么?
- 主键索引自增,这样每次插入新数据都是追加,不需要移动甚至页分裂
- 索引最好设置为 NOT NULL
- 联合索引中,把区分度大的字段放在前面