Types and Uses
观测主要有三个目的:
- 生成警报,指示系统存在严重问题;主要靠 cloud infra 或 container management system 收集的 metrics,比如 CPU、内存、网络利用率等。
- 取证和排查问题,即 forensics,这时候最有用的是 logs,通过日志可以倒推发生了什么
- 性能分析,收集 traces 用来理解一次请求在整个系统里从头到尾都经历了什么,时间花在哪些地方
Measurement Architecture
收集测量数据的核心思想是集中化:数据来源分散在各个服务、各个节点上,但分析时不可能 ssh 到几十上百台机器上看,所以要把所有 measurement 数据汇总到一个后端系统里,通常是一个数据库。
例如,要判断一个 service failure 是软件问题还是硬件问题,就有必要检查同一个服务的不同实例、以及同一台机器上的不同服务的状态。
Sources of measurement data
数据来源分为两类:
- 基础设施层面自动采集的指标,比如 VM 或容器的 CPU、网络、磁盘,这些通常由云平台、autoscaler 或 service mesh 的 control plane 提供;通常,后端会有一个专门的服务来检索 infra metrics 并存到数据库里。
- 服务自己产生的日志。服务将日志写到本地文件系统里,然后靠一个后端 agent 收集和转发。日志量通常很大,所以 agent 往往还要负责清空本地日志,否则可能会耗尽磁盘空间。
Activities of the backend
Backend 要做几件事:
- 根据一系列类似于 autoscaling 的规则判断是否要发 alert 或 alarm
- 提供 dashboard,可视化系统状态
- 支持 drill-down,从聚合指标深入查看具体实例
- 做长期分析,如统计常见故障、修复时间,用来改进开发和运维流程
分布式系统中的 Time Coordination
Why time is not suitable for determining the sequence of activities in a distributed system?
即使是在单机上,时间的精确性也很困难(硬件时钟漂移,网络延迟、物理因素等)。即使有 NTP、原子钟、GPS,也只能把误差压到毫秒级甚至更小,但在分布式系统里,这已经足够不精确。
Coordinating time across two or more devices is a very hard problem, and discussions about this subject quickly shift from engineering issues like the speed of light to metaphysics. For example, my “now” is not your “now”: If you create an event source and I observe it, when does the event occur? In your frame of reference, or mine?
时间不能用于确定延迟,例如不同设备之间的延迟,更重要的是,时间不能用于对不同设备上发生的事件进行排序。
因此,分布式系统通常不用 timestamp 来决定跨机器事件的先后顺序。系统设计上应该避免依赖全局时间,而是用专门的机制,比如 vector clock,去表达“先发生于”的关系。
Logs
日志主要用于事后分析和排障。如果某个服务出现故障,analyst 需要了解导致问题的事件顺序以及传递给服务的参数值,然后能反向推演,重现问题发生的过程。Analyst 可以先制定 quick fix,随后再确定 long-term fix 以防止问题再次发生。
日志是服务自己负责生成的,记录“发生了什么”。任何日志记录操作都会消耗资源: 创建需要处理时间,写入需要磁盘带宽,存储需要空间,将日志复制到中心位置需要网络带宽。接下来会讨论日志中应该记录什么、以及如何保存。
What Events Should be Recorded?
服务应该记录技术信息和业务信息,下面关注前者。
最低要求是每个请求进入和离开服务时都要记录一条,这样至少可以计算 latency。更细一点,可以在关键函数进出时打日志,帮助定位服务时间都花在了哪些地方。除了时间和 error 之外,日志里还应该包括调用方、参数、返回值、错误码,以推断下游服务的 availability。
另外,在分布式系统中,如何关联跨服务日志非常关键。因为无法依赖 timestamp,所以所有服务必须采用统一的日志消息 identification,例如给每个请求一个唯一 ID,然后一路传递,每个服务写日志时都带上这个 ID,这样才能把整个请求在不同服务里的日志拼起来。HTTP header 中的 context field 就可以这样使用;这就是现代分布式 tracing 的思想雏形。
Where Is the Recording Saved?
单个实例先把日志写在本地标准位置,例如 Linux 下的 /var/log/servicename。这些本地日志会定期通过 agent 转发到 Log aggregation infra(Logstash, Splunk, Kibana, etc.),后者有一个 time-series database system。
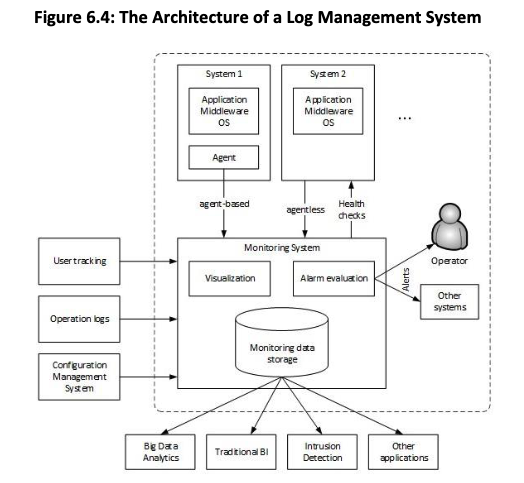
日志输入时通常还是纯文本,需要靠解析规则把各字段识别出来,存进 time-series database。
Metrics
Metrics 是衡量服务在一段时间内活动情况的指标,比如 10:00:00 - 10:59:59,承载服务的 container 的 CPU 利用率不到 10%。由此可以看出 logs 和 metrics 的区别:
- 日志记录服务内部发生的事情,metrics 记录服务外部可见的情况。虽然知道 CPU 利用率不到 10%,但是不知道服务内部的时间都消耗在了哪里。
- Metrics 是 OS 或平台测量的数据,日志是服务生成的,需要 post-collection analysis,因此 metrics 可以用于触发实时警报,而日志用于事后分析问题。
日志和 metrics 可以合在一起分析,比如用日志标出某个功能被使用的时间段,再对比那段时间的 CPU 使用率。
Tracing
日志 entries 代表单个事件,仅凭日志很难构建出 transaction 的 end-to-end view,而 tracing 可以构建这种 view。
请求一进入系统,就会被分配一个 trace ID,通过 HTTP header 一路传递。trace 由多个 span 组成,每个 span 是一个有名字的时间段,对应一次调用或一个阶段。把这些 span 画出来,就可以直观地看到瓶颈在哪里。
此外,每条 trace 都可以关联一个 context,它能控制服务的行为或进行后续分析。Context 几乎可以包含任何内容,例如测试版本、系统、流量 prioritization 等。因而,trace 不只是性能分析工具,也可以用来做流量区分、优先级控制、实验分流之类的事情。