Shared memory model
线程:独立的 execution flow,通常共享内存
-> process 有独立的内存,一个 process 里可以有若干个 thread,它们复用 CPU 资源,通常由 OS 管理、切换
shared memory model:程序员显式地创建多线程
- 它们有各自的局部变量栈
- 所有 load/store 操作都对同一套共享内存(所有线程可读写)
- 线程切换可能在任何时候发生
- 通过 thread-level parallelism (TLP) 执行并行工作
Interleaving
e.g. initially x=0, y=0
thread 1:
store 1 -> y
load x
thread 2:
store 1 -> x
load y
因为线程可能随时切换,最后两个线程 load 出的值可能是 x=0,y=1 / x=1,y=1/ x=1,y=0
最简单的 multiprocessor 是把整条 processor pipeline 复制一次,除了 cache 是共享的
多线程的操作 (load/store) 是“随机” interleave 的,load 的值是最近一次 store 的值(可能不是当前线程的 store)
shared memory 的四个问题:
- cache coherence:如果每个核有 private caches
- parallel programming
- synchronization:如何管理共享数据的权限,实现 lock
- memory consistency models:编译器优化、store buffer、乱序执行
hardware multithreading (MT)
动态共享一条 pipeline,只复制 PC 和寄存器;硬件 interleave 指令
Cache coherence
使用 private cache -> Cache Coherence Protocol 一致性协议
Loads read the value written by the most recent store
要同步不同 core 的 cache,需要做到两点:
write propagation:某个 core 的 cache 更新时,必须传给其他 core
transaction serialization:某个 core 里对 cache 的操作顺序,在其他 core 看起来顺序必须一致
VI
- Valid/Invalid
- track 每个 block 的 copy
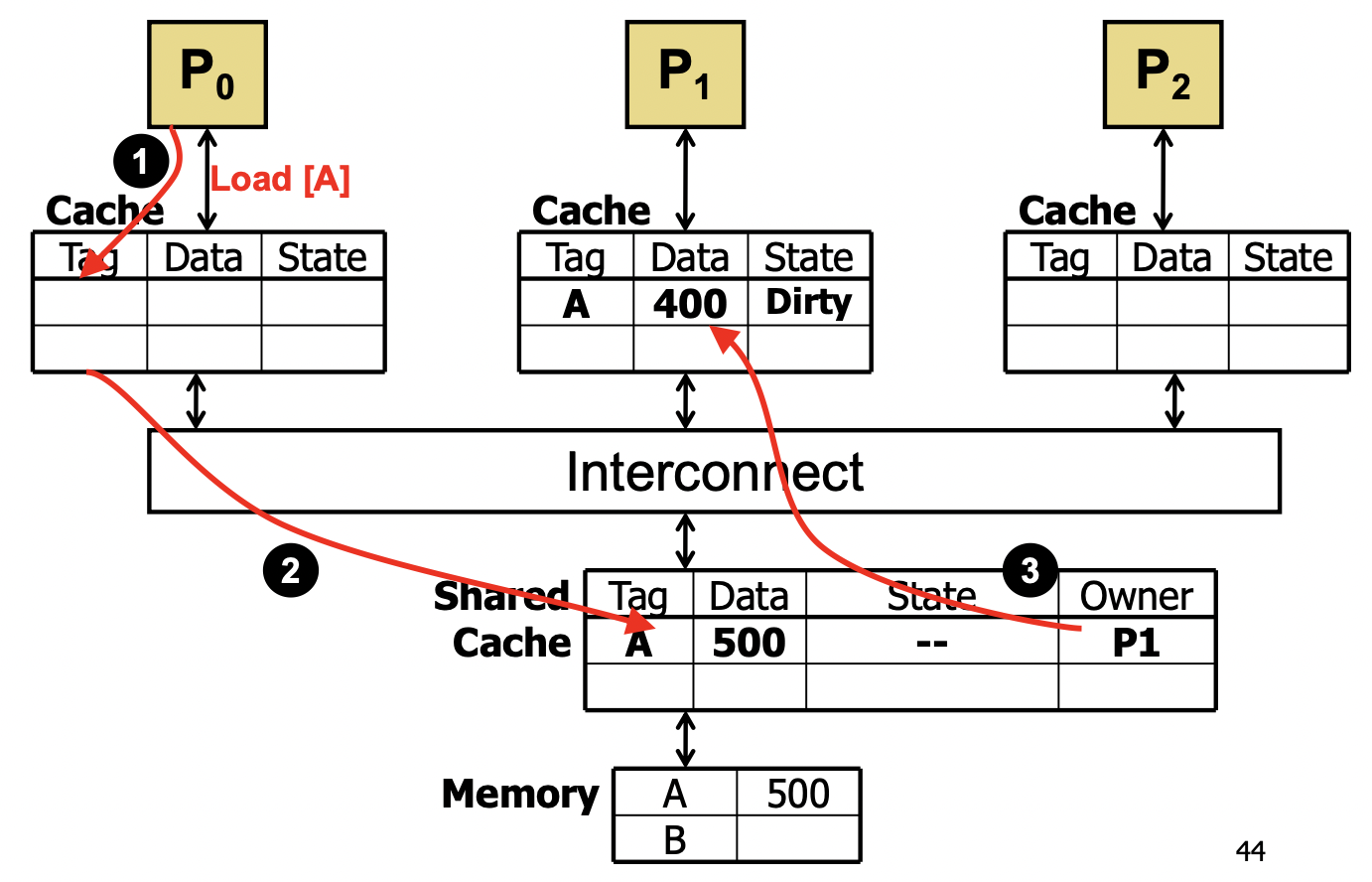
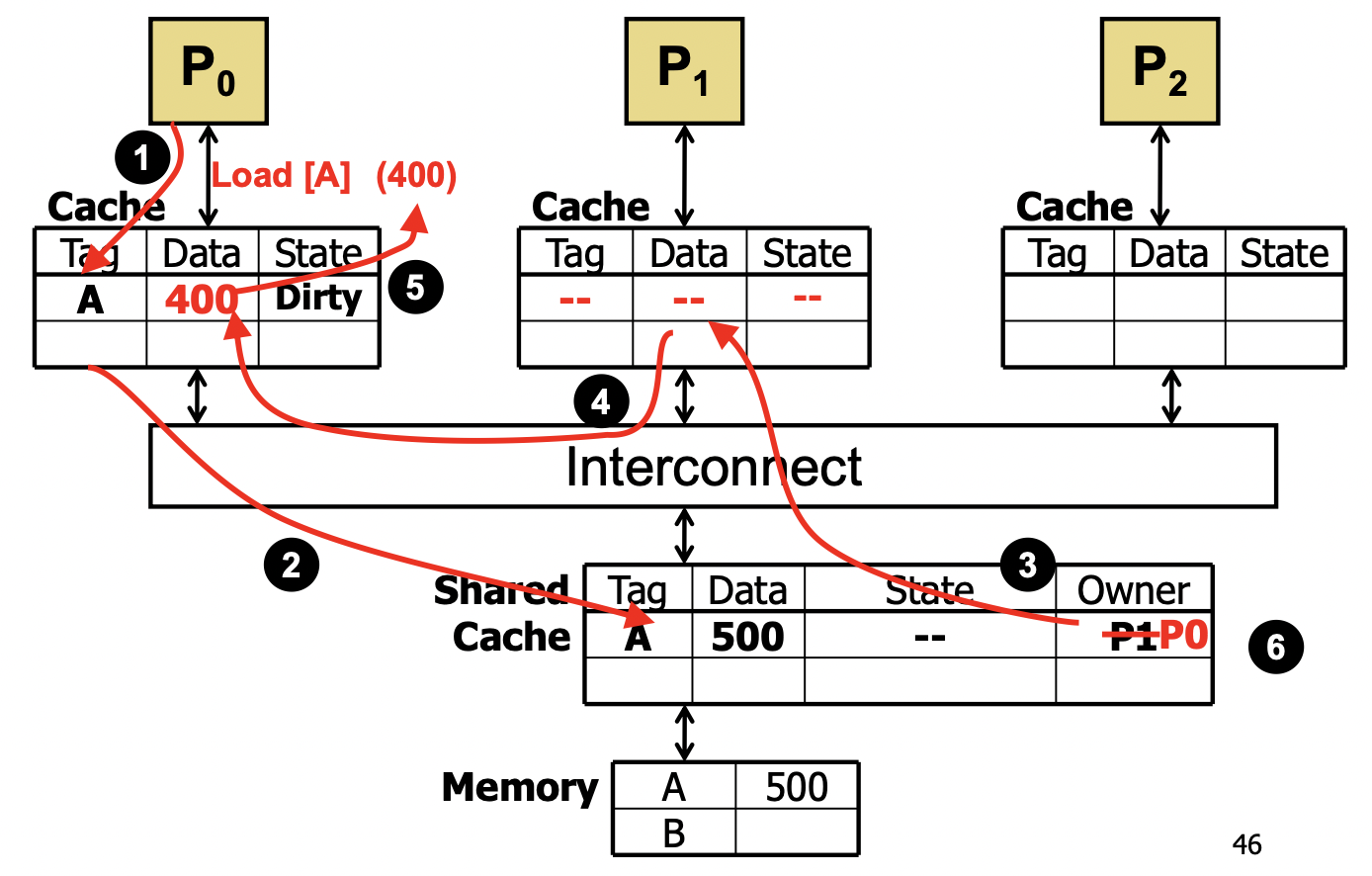
- 如果有一个 core 想写 block -> 其他 block invalidate
- Invalid 的 block 要读时,如果某个 core 的 copy 是 dirty 的,就写回
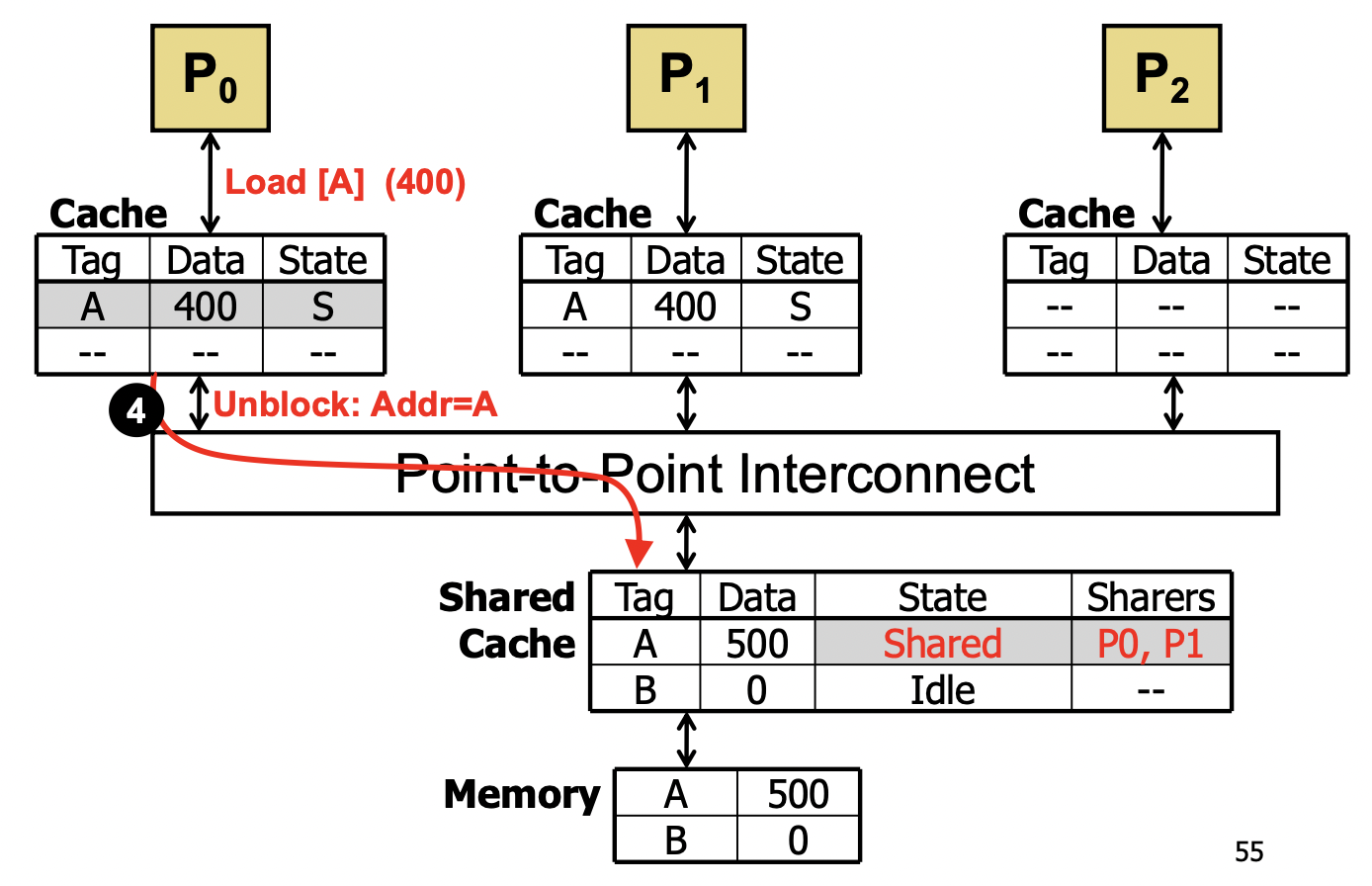
MSI
- Modified (r/w permission,相当于 local dirty copy)/Shared (read-only,相当于 local clean copy)/Invalid
- 允许多个 S-state 或一个 M-state
- 有一个 core 想写 block 时,自身变为 Modified,其他 block 变为 Invalid;
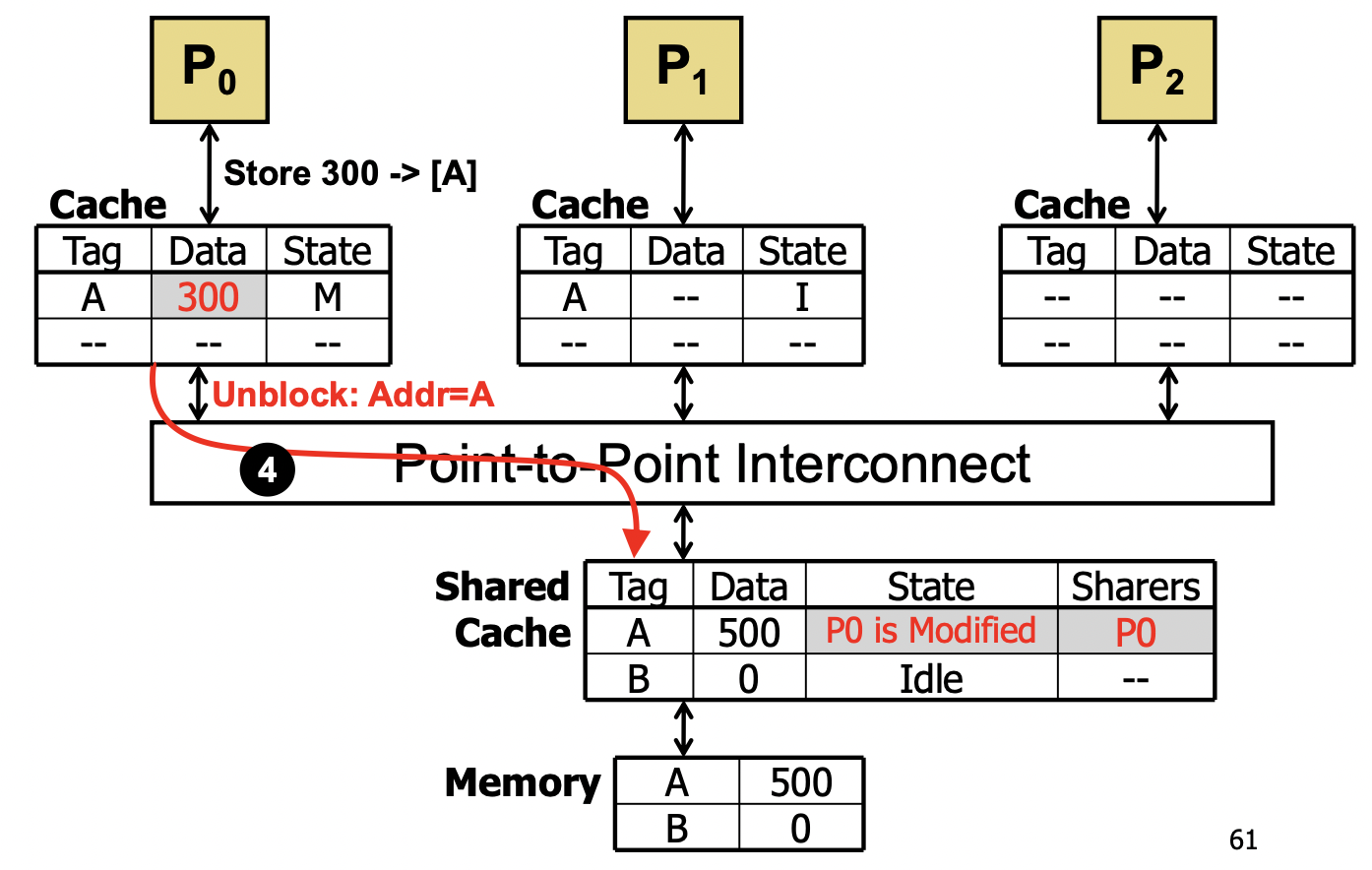
- Invalid 的 block 要读时,Modified copy 写回,然后它们两个变为 Shared。
- 引入了两种新的 cache miss
- upgrade miss:往 read-only blocks 里写
- coherence miss:miss to a block evicted (write-backed/replaced) by another processor’s requests
- false sharing:共享了同一个 block 的不同部分,并不是真的 sharing,会造成乒乓效应

- Modified (r/w permission,相当于 local dirty copy)/Shared (read-only,相当于 local clean copy)/Invalid
MESI
- 增添了 Exclusive state: “I have the only cached copy, and it’s a clean copy”
- Load miss 后如果没有其他 block copy,则变为 Exclusive
- 写 Exclusive 会将其变为 Modified
- block eviction (writeback/replacement) 时:如果是 Modified 就必须写回,Exclusive 则不必要写回
- 避免了 non-shared blocks 的 upgrade miss
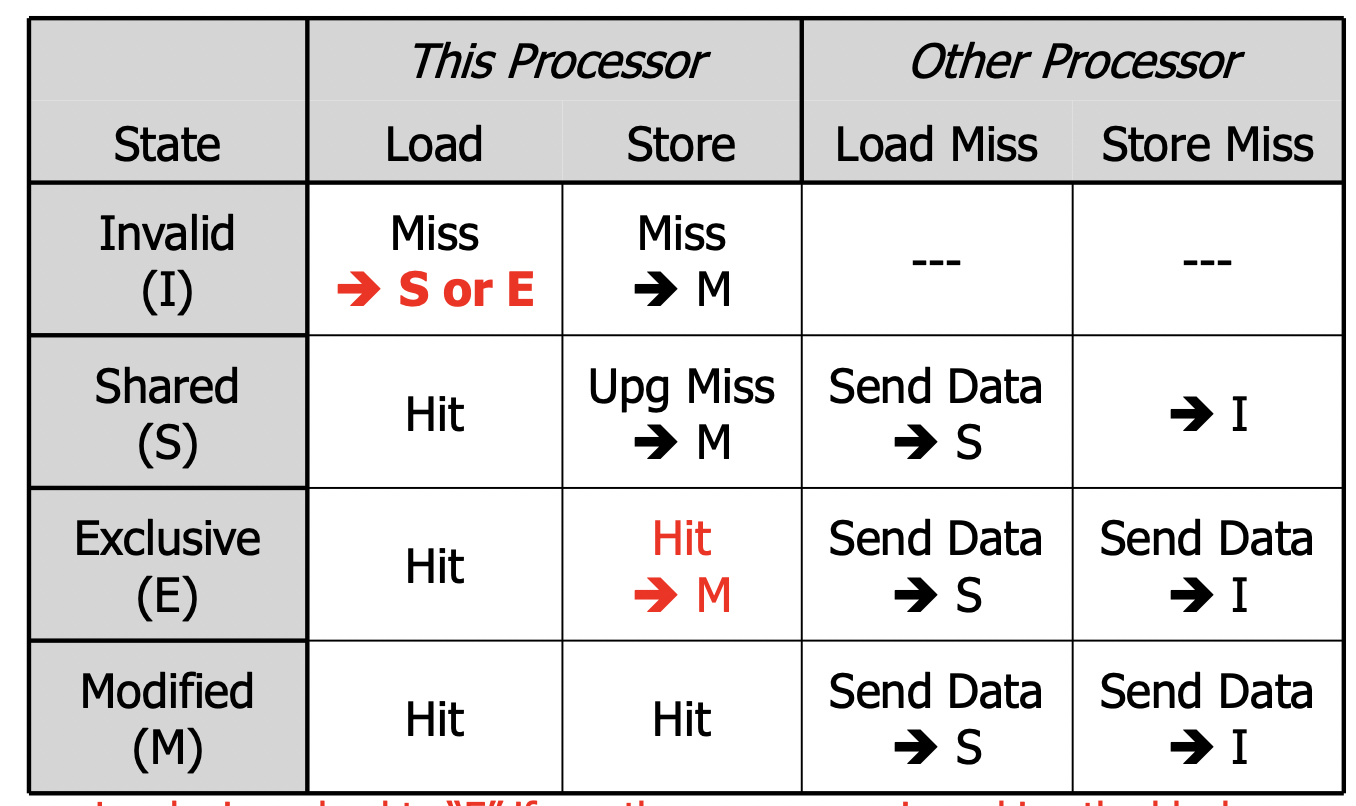
- 增添了 Exclusive state: “I have the only cached copy, and it’s a clean copy”
MOESI
- dirty bit 和 coherence state 有冗余 -> 将 dirty bit 加入 coherence state
- 把 Shared 分为 Shared 和 Owned,前者 always clean,后者 always dirty
- dirty bit 和 coherence state 有冗余 -> 将 dirty bit 加入 coherence state
- 两种类型
- 对所有 caches 进行 write-through update(浪费 bandwidth)
- invalidation,两种类型:
- bus snooping/broadcast
- directory:track block sharers(bandwidth 较低,但延迟更长,常用),两种选择:
- inclusion:在 per-core cache 中的必须在上级 cache 里
- no inclusion
参考资料:
cache之多核一致性(二) - MSI协议
一小时,完全搞懂 cpu 缓存一致性
Synchronization
共享内存的重要问题;lock/semaphore
-> acquire (lock) and release (unlock)
另一种方式是 barrier synchronization
lock implementation
如何实现 acquire/release?
ISA 提供了原子的 lock acquisition 指令,实现了正确的 spin lock -> atomic compare-and-swap (CAS),其原理类似:
if (this == expect) {
this = update
return true;
} else {
return false;
}
即,需要给出一个变量期望值,如果实际值与之不相等,表明变量已经被其他线程修改过了。
-> CAS 不是真正的 lock,没有 lock/unlock 过程,不存在阻塞,对死锁问题天然免疫;失败的线程不会挂起,仅是被告知失败,并且允许再次尝试
CAS 由多条指令实现,如何保证其原子性?
label:
load-link r1 <- 0(&lock)
// potentially other insts
store-conditional r2 -> 0(&lock)
branch-not-zero label // check for failure
在 load-link 时,处理器记住了操作的内存地址;如果检测到写操作,下一条 store-conditional 会执行失败。
CAS 的缺陷:循环时间太长、只能保证一个共享变量原子操作、ABA 问题
queue lock:每个等待的处理器 spin on 不同位置(一个 queue);当一个处理器 release lock,只有下一个才能看到它被释放了,其他处理器全都不知道,这样可以按顺序传递 lock
Locking issues
- locking 颗粒度问题
粗粒度的 lock (i.e. 整个数据库只用一个 lock)很容易正确,但限制了并行度;细粒度的 lock 可以实现多个 critical sections 的并行操作,但非常容易出错
- 死锁:循环等待共享资源
-> 四个 Coffman Conditions,只要打破随便一个就可以解开
多个 lock 时,总是按照同样的顺序 acquire
- acquiring lock 不仅代价极高,而且多数情况下并不需要;我们是在为极少数的冲突付出代价
Memory Consistency
initially flag = 0, a = 0
thread 1:
store 1 -> a
store 1-> flag
thread 2:
loop: if (flag==0) goto loop
load a
上面的例子里,load a 也可能会返回 0 -> 针对不同地址的内存操作重排
consistency 和 coherence 的区别:后者考虑同一内存位置的写操作对所有处理器的可见性,保证其顺序;前者不仅针对同一内存区域的访问,而且读写两种操作都要考虑。
考虑到并行优化,几乎所有平台都会改变指令顺序来提高程序运行速度,这不可避免地会违反 Consistency 原则。前面提到存储的 Consistency 模型中的内存访问分两种,即读和写。经组合,易得违反 Consistency 原则的情况也可能有四种:R-R hazard,R-W hazard,W-R hazard 和 W-W hazard。过强的 Consistency 约束会使优化程度极大降低,因此很多平台会选择放弃其中的一种或几种。
几种 memory consistency 模型:
- sequential consistency (SC):最严格的原则
- 内存访问都是原子操作,没有 write buffer/cache
- 核内严格按程序要求的顺序完成 load/store 指令
- 多核之间可以 interleaving
- total store order (TSO)(x86)
- 允许 FIFO 的 write buffer
- store 可以延迟,但必须按顺序进入 cache
- 放松 W->R 顺序
- 可以使用
FENCE这一 memory barrier 保证核内操作顺序
- 允许 FIFO 的 write buffer
- release consistency (RC)(ARM/PowerPC)
- store 可以乱序进入 cache,load 也可以重排
- 用 acquire/release 作为 memory barrier(前向和后向)
参考资料:内存一致性(Memory Consistency)