Superscalar
scalar pipeline 的性能极限是 CPI=IPC=1,但限于 hazards 也无法达到
multiple issues -> superscalar
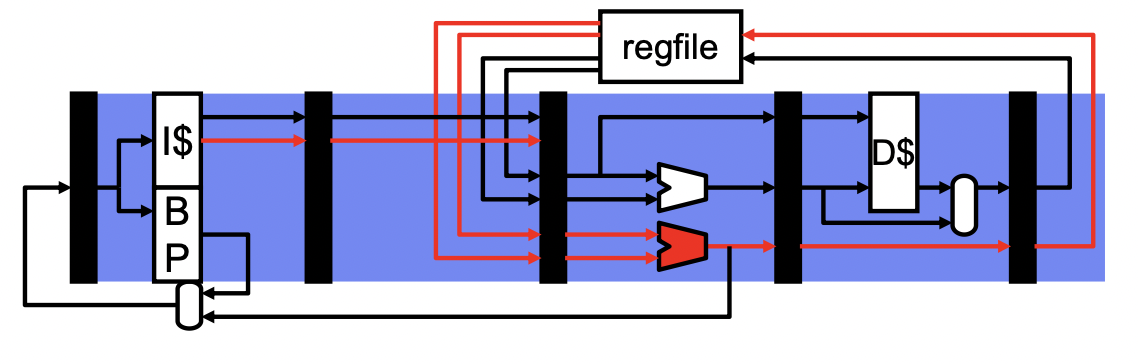
要多套硬件同时执行多条指令(指令级并行 ILP),需要检查它们的依赖关系
寄存器调度,并行度取决于 workload
目前大部分是 4 inst/cycle
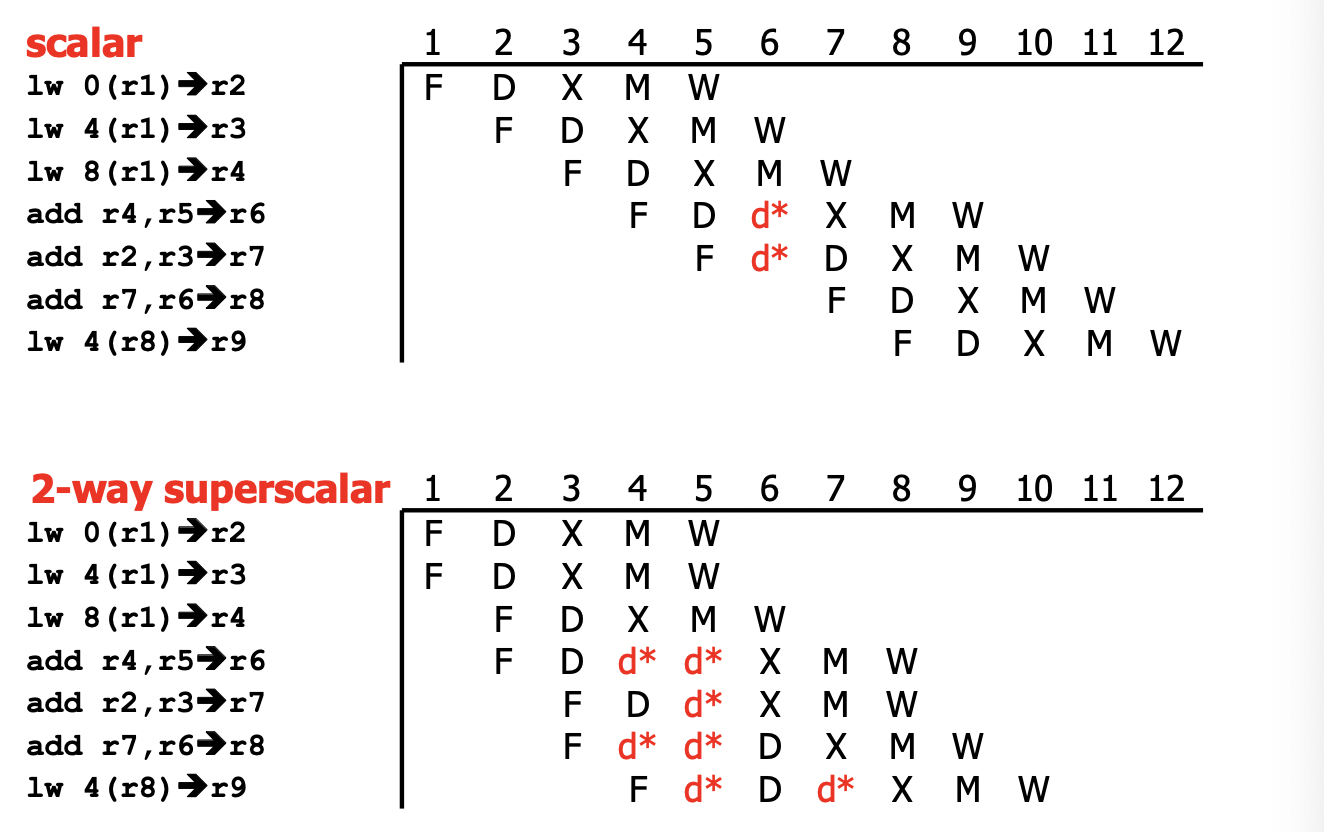
Superscalar Implementation Challenges
取指时遇到的问题:
- cache 连续问题:如果取的指令不在同一个 cacheline 中,宁可放弃
- 分支预测:average number of inst per taken branch
solution:
- over-fetch and buffer
在 fetch 和 decode 之间增加一个 queue - loop stream detector
识别出一个 loop,就整个放入 small cache 中
没有命中时需要重取
后端的问题:
- 多个 ALU;硬件是否共用,权衡冲突和 latency 等
- bypass 需要检查的依赖关系是 N^2 级的
- clustering ALUs and regfile
VLIW
VLIW: very long inst word 多个操作封装进一条指令
constant operation latencies are specified
完全靠编译器确保一条指令里没有依赖
编译器要:
- 调度指令
- 保证超长指令字内部的并行
- 避免 data hazards,通常用 NOP 隔开
software pipelining:loop 内部 iteration 之间重叠
每次 iteration 分配一个新的 reg set -> rotating register file
没有 loop 时 trace scheduling:找到一条 hot flow paths,合并途径的 block,其他分支增加 repair code
VLIW 的问题:
- 兼容性不好,每次换硬件,编译器就必须重新设计
- NOP、循环展开都增加了代码长度
- 内存操作的 latency 由于 cache 问题并不固定
- 分支的并行性
Superscalar vs. VLIW
superscalar 硬件和调度比较复杂,但可以 handle 动态的 unpredictable 指令流;
VLIW 完全依赖编译器调度,硬件简单,适用于静态和 predictable 指令流。