以 cache block 为单位 fetch the data before needed by the program,需要预测地址
- 减少 compulsory cache misses
- 减少内存 latency:L2 的 miss rate 减小,L1 的 latency 就会减小
如果取错了:占用空间和带宽,但不用刷新 pipeline,影响很小
问题:取什么、什么时候取、在哪里放 prefetched data 和 prefetcher、怎么取
取什么:
- 根据过去的 access patterns 预测
- 编译器/程序员的 knowledge
何时取:
- 太早或太晚都不行,影响 prefetcher 的 timeliness
- 把 prefetch instructions 在代码里提前
取到哪里:
- prefetch 哪层 cache:levels/between levels
- 要放到 LRU 链表的哪个位置/是否就当作 demand-fetched block?
- prefetcher 放在哪里,取决于它观测的是哪层的 access patterns
- 要看到更完整的 pattern 就开销更大
怎么取:
- software:把 prefetch inst 插入代码中,适用于规律的 access patterns
- hardware:硬件监测内存 access,自动生成 prefetch 地址
- execution-based
preformance 指标:
- accuracy (used prefetches/sent prefetches), coverage (prefetched misses/all misses), timeliness
- bandwidth consumption (memory bandwidth consumed with/without prefetcher)
- cache pollution:替换出去原有的 block 导致额外的 miss
Software Prefetching
for (i=0; i<N; i++){
__prefetch(a[i+8]);
__prefetch(b[i+8]);
sum += a[i]*b[i];
}
while(p){
__prefetch(p->next->next->next);
work(p->data);
p = p->next;
}
很难决定要提前多少 prefetch/插入 prefetch 的 inst
profile the code,计算 loads that are likely to miss,以及不同 prefetch 和 miss 的距离
Hardware Prefetching
特殊的硬件观察 load/store access patterns
可以基于系统实现,不依赖于上层应用/inst,更 flexible;但硬件比较复杂
next-line prefetcher:取 demand access 之后的 N 行 cache line
prob:规律访问,但 access stride = 2 and N = 1
-> stride prefetcher 识别 stride(基于 inst/内存访问)
- Instruction-Based stride prefetching
把 load inst PC 存入表中,学习其间隔
timeliness prob - memory-region-based stride prefetching
记录访问的 addr
stream prefetching is a special case
更复杂的 access patterns:
- complex regular
- multi-stride detection -> path confidence based lookahead prefetching
- spatial memory streaming
- online RL
- irregular
Execution-Based Prefetching
load 操作非常慢,cache miss 时 pipeline 要 stall
乱序执行:增加一个 buffer 按序放置正在 pipeline 中 stall 的 inst,先执行后面 independent 的(runahead),把结果放进 buffer,等前面的指令执行完了,按序提交
-> buffer 满了之后设置一个 checkpoint,继续往后执行,虽然结果可能不对,但是 prefetch 了这些 inst 需要的 cache,stall 结束后再 restore ckp, flush pipeline,重新正常执行
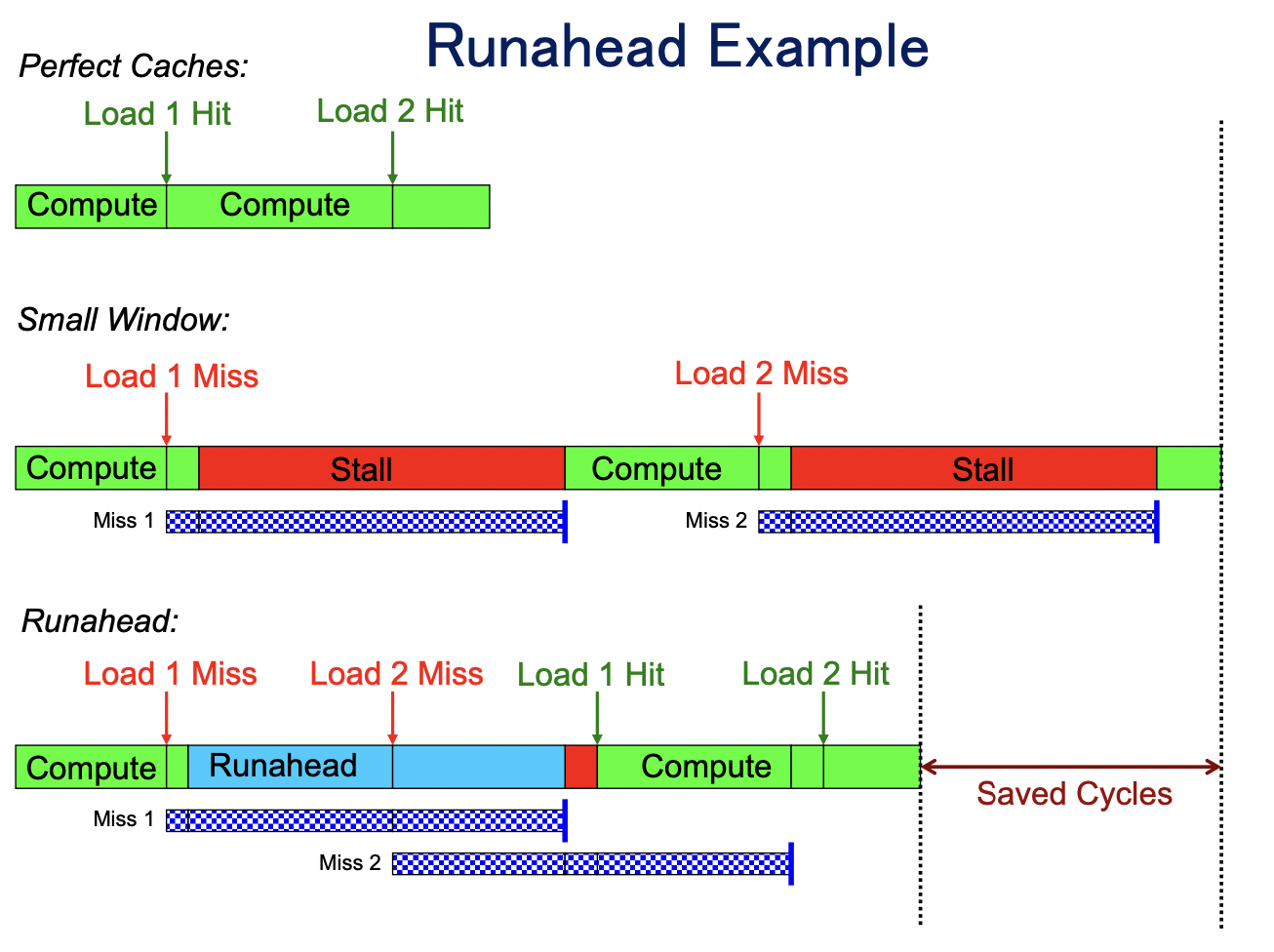
- very accurate prefetches
- 有 branch 时受限于 branch prediction
- 无法 prefetch dependent 的 cache