Overview of Memory Arrays
计算机如何存储数据?
- memory array 存储阵列
- 2^N 行 M 列,每行对应一个 word-line,每列对应一个 bit-line
- 每次读一行,activate 一个 word-line,输出一行的 storage
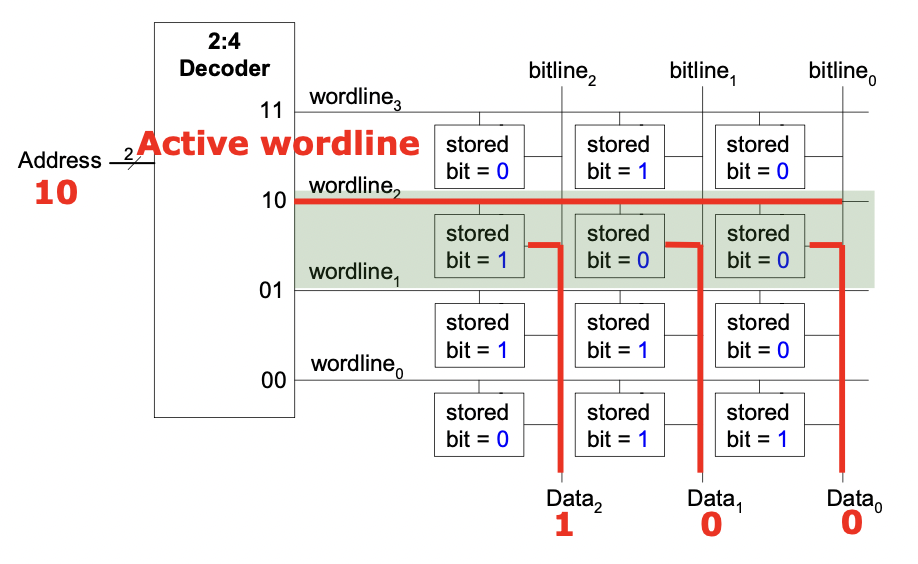
更大的内存:需要降低 access latency,允许并行访问
思路:将内存分割成比较小的 array (banks),将其连接到输入输出总线上,bank 在同一周期/连续周期可以独立访问
-> hierarchical array structures: channel -> DIMM -> rank -> chip -> bank -> row/column
DRAM and SRAM
RAM (random access memory) 之所以称作「随机存取」,是因为相较于早期的线性储存媒体(磁带)而言,因为磁带的存取是线性的,存取时间会依目前磁带位置和欲存取位置的距离而定,需转动磁带至应有的位置,距离越长、转得越久、存取时间也就越久。而 RAM 没有这种烦恼,存取时间为固定值,不会因为数据在内存的位置而影响存取时间。
- DRAM:容量较大、存取时间较慢、相对便宜
主存使用;电容储存,会随着时间渐渐 lose charge,需要 refresh 以保持数据 - SRAM:容量较小、存取时间较快、相对更贵
cache 使用;flip-flop 储存
读取数据的步骤:
- decode 行地址,activate word-line
- 读出这一行的数据,写进 row buffer (sense amplifier)
- decode 列地址,从 row buffer 中选择对应的数据,发给输出总线
- 为下次访问 precharge bit-line
The Memory Hierarchy
bigger is slower, faster is more expensive.
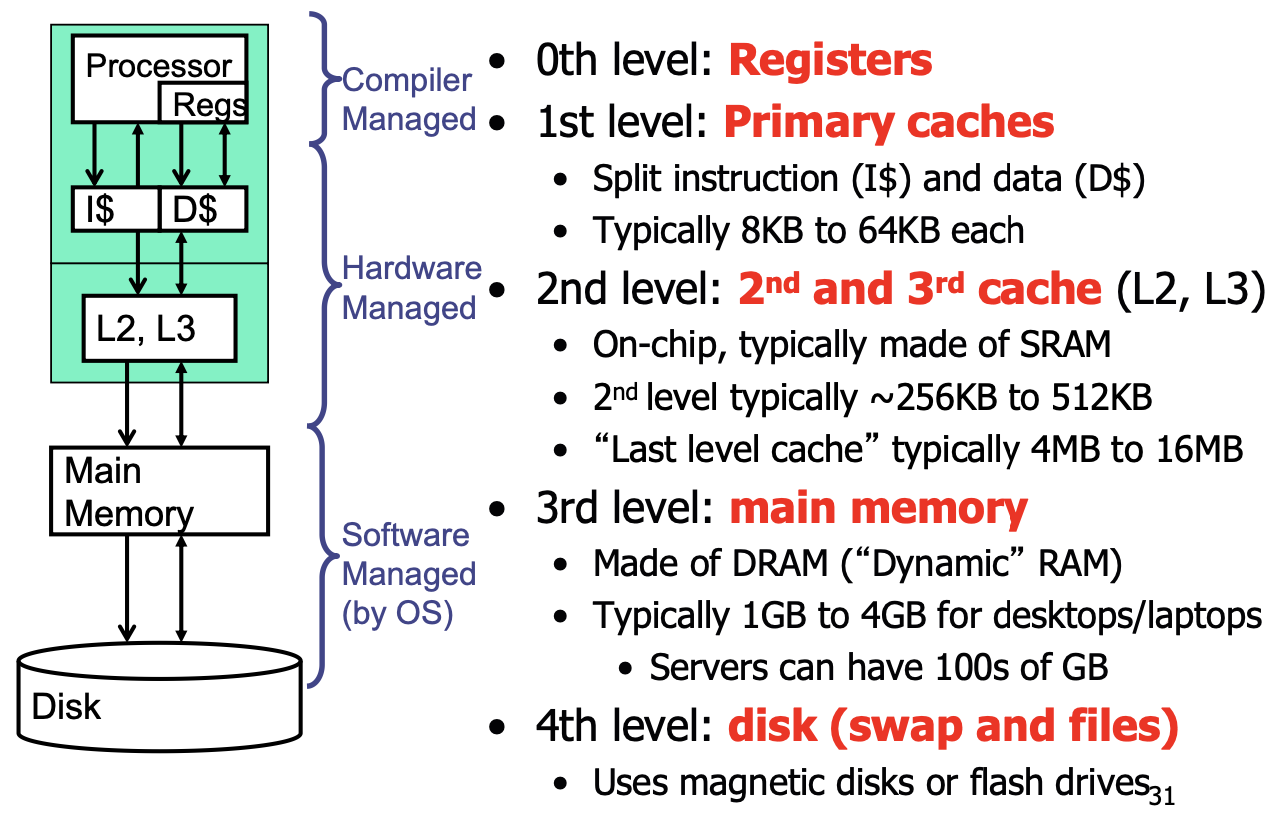
不同层次的存储用总线连接。
Cache Basics and Operation
- 单位 block/line
- hit/miss
- 一些重要的设计策略
- placement: where and how to place/find a block
- 替换策略
- granularity:block 的大小
- write policy
- 指令/数据是否要分开处理
Placement
memory 被分为固定大小的 block,每个 block 通过地址中的 index bits 确定在 cache 中的位置
三种映射方式:
- full associativity 全相联:内存地址可以映射到任何一个 cacheline
- 内存地址 = tag + offset,检索时直接比对所有 cacheline 的 tag
- direct-mapped 直接映射:多对一,一个内存块只能映射到唯一的 cacheline
- 内存块号 j mod cache 行数 m = cache 行号 j
- 内存地址 = tag + 块号 + offset,通过块号找到 cacheline,比对 tag
- 组相联:内存块只能映射到唯一的组,但可以是组内任何一个 cacheline
cache 组成如图:
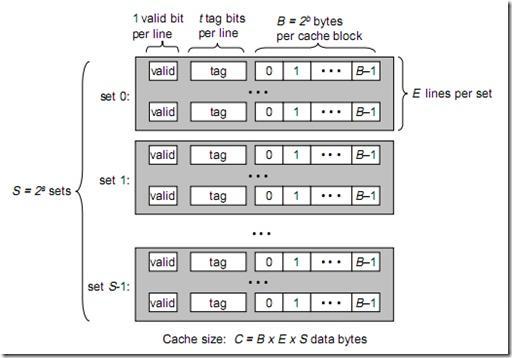
cache 分为 \(S=2^{s}\) 个组,每组有 E 个 cacheline;每个 cacheline 中有 \(B=2^{b}\) 个字节。
(要注意在说 cache 容量时指的是什么:只有存储的数据,还是包含前面的 valid 位 + tag + 可能的 dirty 位等?)
cache 地址:行号 + offset
内存地址由三个部分组成(tag + index + offset),分别对应 cache 的不同组成部分:
- tag 是高 t 位,因为可能会有多个内存地址映射到同一个 cacheline 中,所以 tag 用来校验该 cacheline 是否是 CPU 要访问的内存单元;
- index 是 s 位组索引,可以确定地址映射到了哪个组;
- offset 是 b 位行内偏移,确定了该地址在 cacheline 中的偏移量(哪个字节)。
搜索某个内存地址是否在 cache 中时,首先通过 index 找到组,然后将 tag 与组内所有 cacheline 的 tag 一一比较,某一行相同(且 valid 位有效)则 hit,再用 offset 检索 cacheline 内对应的字节。
如果 tag 没有命中,就从内存中取出一个 block,装进这个组里;如果该组已经装满了,就换掉某个 cacheline(换哪个由替换策略决定)。
更详细的图示:主存和 cache 的地址映射
Associativity
associativity:多少个 block 可以映射到同样的 index(一组有几个 cacheline)?
higher associativity(每个组的 cacheline 更多/组数更少):
- 减少冲突、增加 hit rate
- 但硬件更复杂(更多 comparators)、access 更慢(hit latency 和 data access latency)、tag 位数更多
替换策略
装满了且 cache miss 时替换哪个 block?
- Random
- FIFO
- LRU
- 双向链表实现,把新访问的 block 提到最前面,替换用最后面
- 现代处理器并不实现 true LRU
- 实际上 LRU 和 random 的 hit rate 比较接近
- NMRU (not most recently used)
- Belady’s:replace block that will be used furthest in future (OPT)
- miss rate 低 != 执行时间短 ——为什么?
- 每个 CPU 都有离自己比较近/远的 cache(remote/local),它们的权重不一样,miss 的惩罚也不一样;
- miss overlapping,乱序执行时 miss 可能会重叠,实际相当于掩盖了一部分
- miss rate 低 != 执行时间短 ——为什么?
Write Issues
- Write Propagation
- Write-through 直写:cache 一更新,就更新主存
- 需要额外带宽
- 有时候只写很少的字节 small writes,但需要以 block 为单位操作,有很多不必要的操作
- 节省了 dirty 位的空间;简化了 miss handling
- 经常用在 GPU 中,因为不太具有时间局部性,不需要数据在 cache 里多留一会儿
- Write-back 回写:增加一个 dirty 位标记是否被修改过了,踢出去的时候才回写,否则 CPU 读写的都是 cache
- 需要的带宽更小
- 主要用在 CPU 中
- 数据一致性问题:写 L1 的时候不会通知 L2 -> 有可能 L2 和 L1 同时包含一个 cacheline tag,但是内容不同
- Write Miss Handling:写不命中怎么处理?
- Write-allocate 写分配(通常和 write-back 配套使用):从下一层读进 block 里,再写
- 减少了 read miss
- 需要额外带宽
- Write-non-allocate:直接在下一层写
Improve Cache Performance
- Cache size
- 太大:增加 hit/miss latency,越大越慢
- 太小:无法很好地利用时间局部性;经常替换
- Block size
- 太大:block 个数少,时间局部性不够好;空间局部性不明显的时候会浪费 cache space 和带宽
- 太小:无法利用空间局部性;tag 数多
- associativity:每组/index 有几个 block
- 太大(一个组):冲突和 miss rate 最小,但会增加 hit latency(每次需要遍寻整个 cache space)
- 太小:冲突多;hit latency 小
cache misses 的三种情况(以及如何减少):
- 不可避免的 miss:第一次使用某个地址的数据一定会 miss
- prefetching
- capacity miss:cache 太小,没法保留所有需要的数据(同等 capacity 中即使在 fully-associative 里也会出现的)
- 提高 hit rate,和替换和 prefetch 策略都有关
- 观测 computation 的特征
- conflict miss:剩下所有的都算
- 增加 associativity
- victim cache:增加额外的 buffer
- randomized indexing 地址经过 hash 映射,减少冲突
bref. 如何提高 cache 性能?
- 减少 miss rate
- 增加 associativity
- victim cache、hashing、pseudo 二次映射、skewed 更灵活的 block 使用(把 block 的一部分给其他 block 使用)
- 替换策略
- software approach
- restructuring data access patterns/data layouts
- 减少 miss latency
- 多级 cache
- 把关键数据 critical word 先传上来
- sub-blocking/sectoring
- 替换策略
- multiple accesses 一个周期可以读多次
- 减少 hit latency
Memory Hierarchy Performance
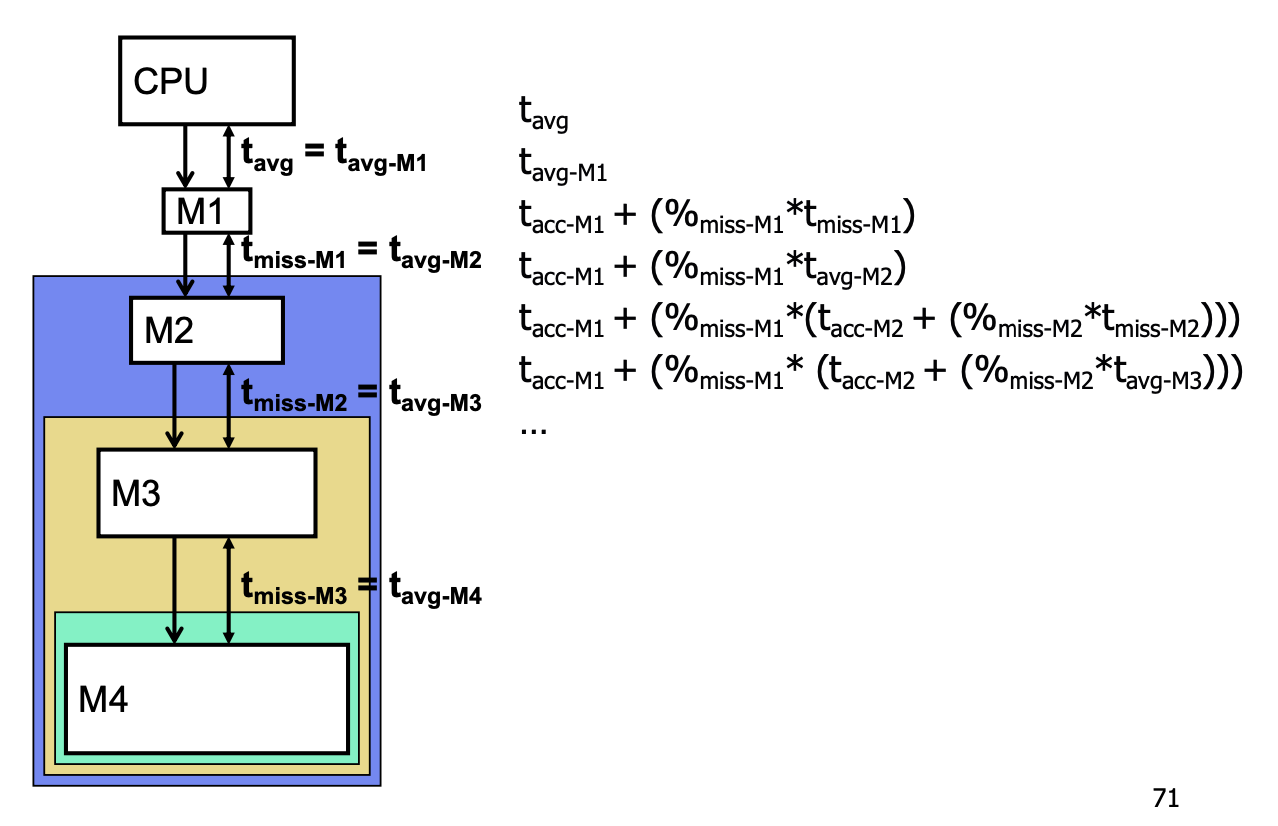
性能计算:
逐层迭代计算:
其他设计策略:
- 指令和数据是否要分开处理
- split I/D 减小 structural hazards 和 access time
- unified I/D 减小 miss rate
- 降低 capacity miss:不用的 inst capacity 可以给 data 用
- conflict miss 会增加
- 多级 cache 是不是包含的关系
- inclusive/exclusive/NENI 三种策略,参考:多层次 cache 的包含关系 和 多级 cache 的包含策略