Control Dependencies
一些可行的 solution:
- 阻塞流水线,直到知道下个 fetch address 是什么
- branch prediction
- 延迟槽 branch delayed slot:在分支指令后面填上(通常是一条)无论是否跳转都会执行的指令,避免预测失败后的浪费
- fine-grained multithreading:干点别的
- 判定式执行 predicated execution:消除 control-flow 指令
- 两边都取指 multipath execution
阻塞意味着 control-flow 指令后的下一条 fetch address 在流水线里至少要经过 N 个周期才能确定;如果每个周期能取 W 条指令(即,流水线宽度为 W),那预测错误就会带来 N*W 个浪费的指令槽
e.g. N=20, W=5, 20% branch
If we fetch 500 instructions with 90% accuracy, it takes 100 (correct path) + 20*10 (wrong path) = 300 cycles, which means 200% extra instructions fetched compared to 100 cycles(if accuracy is 100%).
Branch Prediction
预测错误恢复:flush 掉当前在 ID 和 EXE 阶段的指令(用 nops 代替)
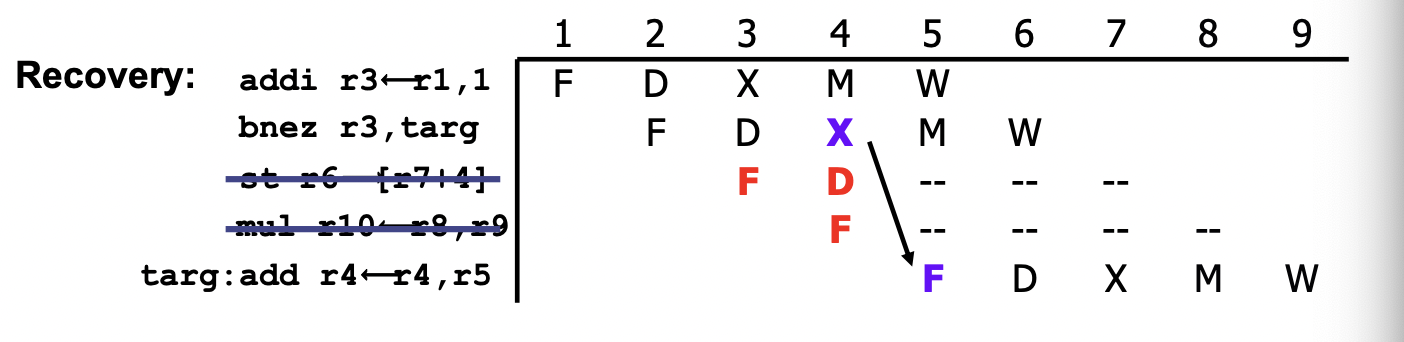
性能牺牲 = 预测错误的概率 * 预测错误的惩罚
-> 两个方面都可以减少
分支预测的几个要素:
- Is it a branch?
- 如果在 ID 之后,看一下 opcode 就可以算出下个 PC;但即使预测对了,也还是有一个周期的惩罚
- IF 阶段后就预测才是真正的 predictor
- Is the branch taken or not taken?
- direction predictor
- If the branch is taken, where does it go?
- branch target buffer (BTB)
Branch Target Buffer
分支目标缓存 BTB 记录已经执行过的分支
思路:很多条件分支指令跳转的 target 总是保持不变,可以记录一条指令的历史跳转记录
具体实现是一个类似 cache 的结构,每条 entry 储存对应 branch 的 target,tag 就是 branch 的 PC
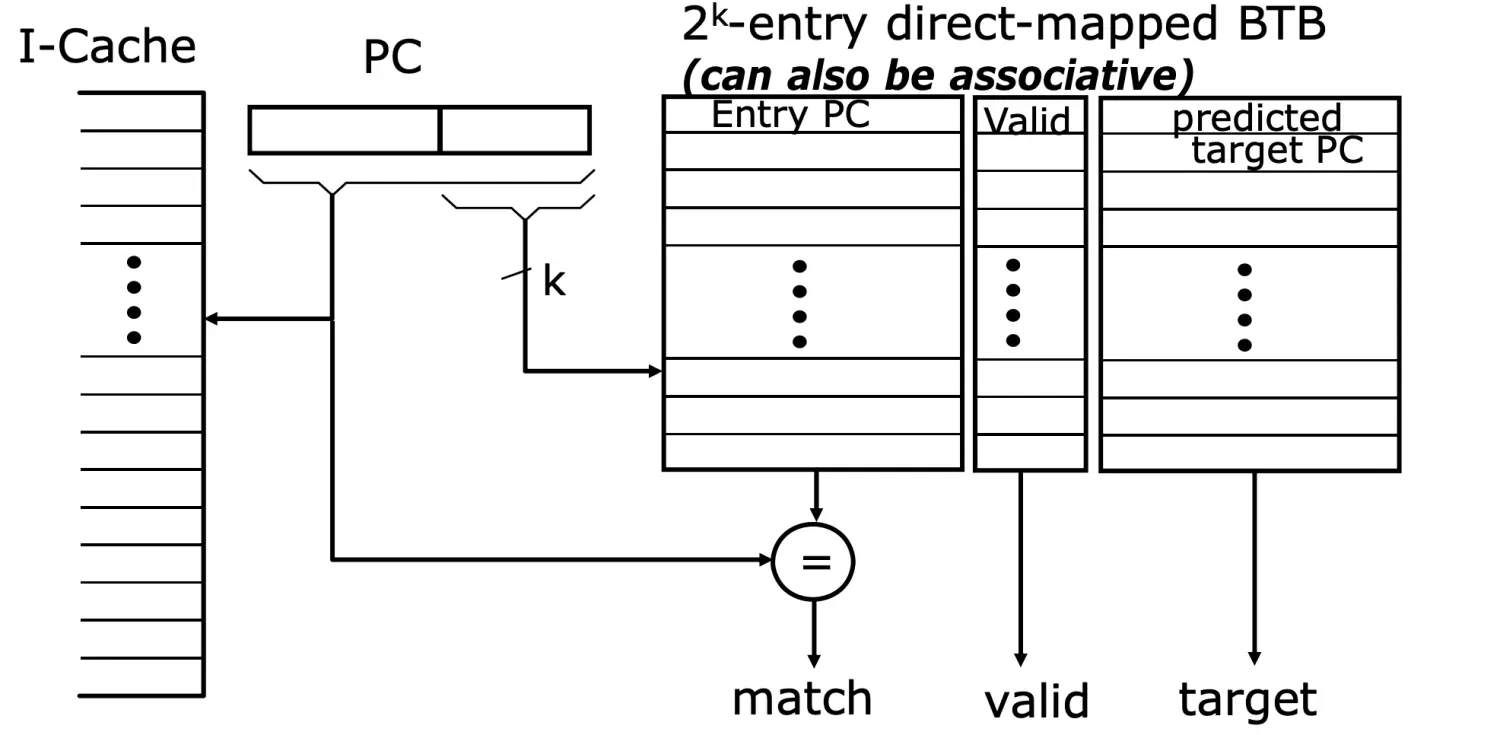
检索 PC,如果命中了某个 tag 就跳转,不命中就当它不是 branch,顺序执行:predicted_PC = (BTB[PC].tag == PC)? BTB[PC].target : PC+4
BTB 针对的是直接跳转(target 是立即数),间接跳转(target 来自值不固定的寄存器)一般有单独的 predictor
Branch Predictor
- 静态分支预测(编译时预测)
- always (not) taken
- backward (loop) taken, forward not taken
- 基于 profiling/program/programmer,e.g. loop always taken, pointer comparisons always not equal
但程序大多数情况下是动态的(比如很多 branch 结果由外部输入决定),静态分支预测的准确率一般不高。
- 动态分支预测(运行时预测)
核心是根据分支历史信息预测,需要额外的 CPU 硬件,latency 也更大
包括两部分:分支结果(是否 taken)、跳转地址
last time single-bit (0=N, 1=T)
- 问题:inner loop branch 会有两个 built-in 错误预测;predictor changes its mind too quickly
Two-bit counter/bimodal prediction (00=N, 01=n, 10=t, 11=T)
- 状态机,有一个“犹豫”的空间
- N iteration 的 loop 的 accuracy = (N-1)/N
- 但是对 TNTNTNTNTN 这种分支没法做出好的预测
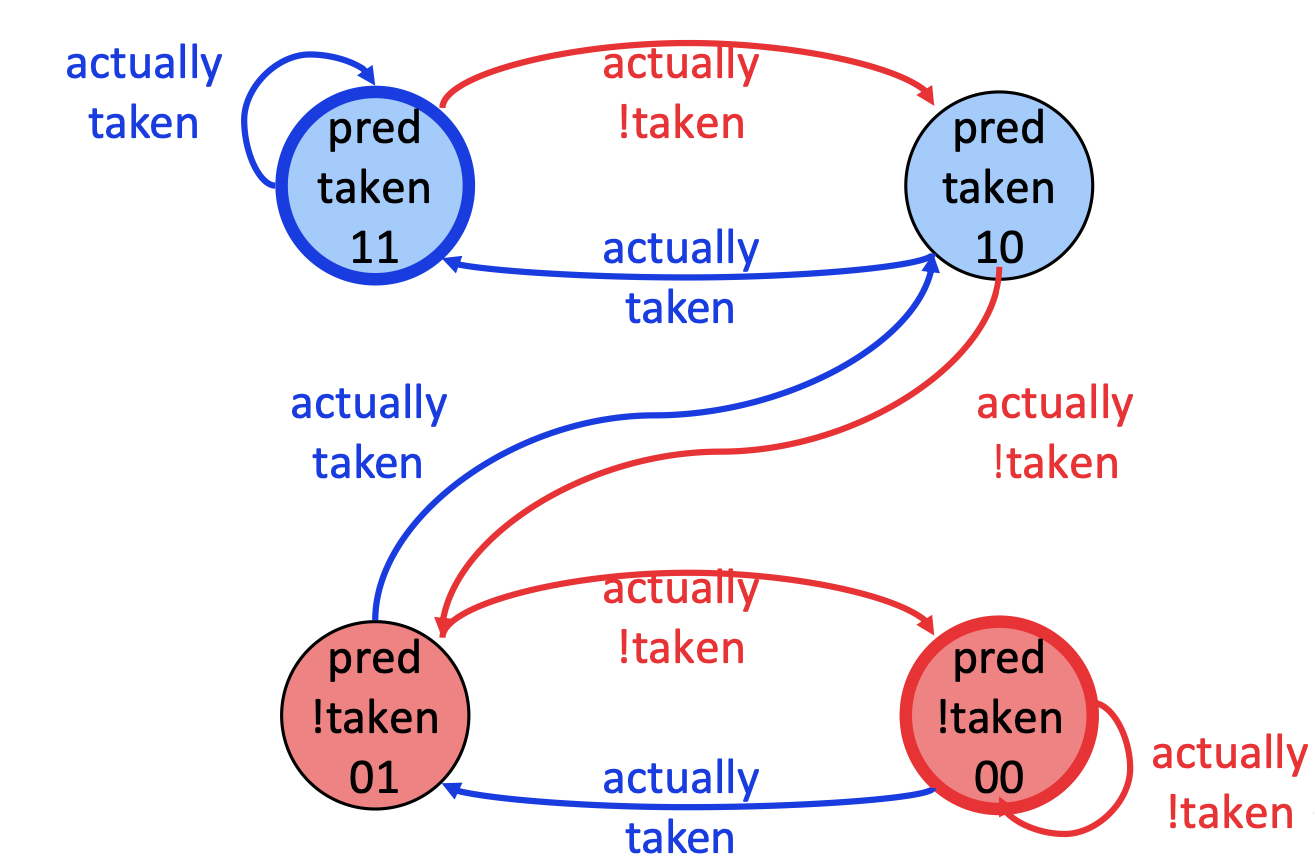
counter 什么时候更新?
一般使用 PC 的一部分寻址 Pattern History Table (PHT),每个 entry 存放着对应分支的 counter -> 可能会出现不同 PC 寻址到同一个 entry,互相干扰 (negative aliasing)
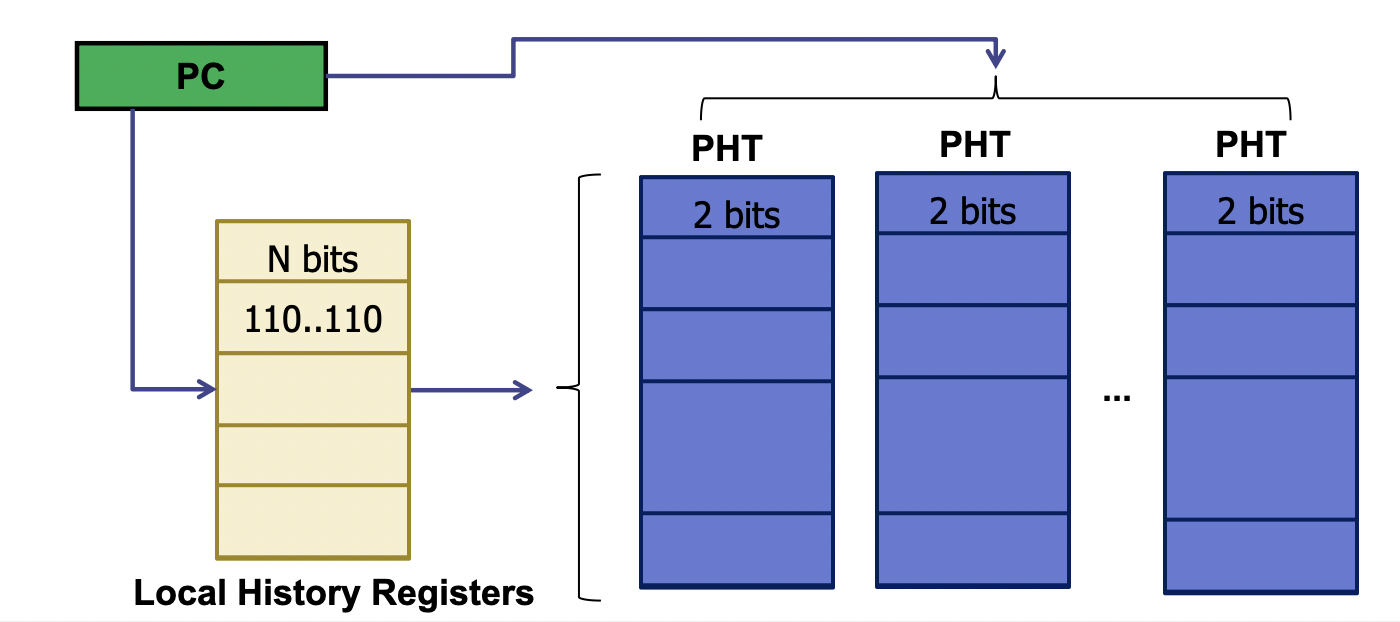
- Two-level (global vs. local)
分支的结果可能和:1) 其他分支的结果;2) 同一条分支之前的结果相关
记录分支的 history,并基于上次同样 history 下的结果进行预测
global branch correlation:
两级 predictor:N-bits 的 global history register (GHR) 记录之前 N 个分支的 direction;Pattern History Table (PHT) 记录之前同样 history 的分支结果
PHT 后面接一个 2-bits saturating counter
improvements:
-> 将 GHR 和分支 PC 使用 XOR hash 寻址 PHT
-> 不同分支使用 separate PHT:用 PC/GHR 确定
local branch correlation 逻辑是一样的,除了把 global history 改成 local history,记录 N 个 history directions
- 混合预测:使用不止一种 predictor,选择最好的
- 不同分支的 predictability 和适用方法不一样
- 可以减少整体的 warmup time
- 需要 selector
- 更先进的算法, e.g. perceptrons
Reducing Branch Penalty
fast branch:在 ID 阶段就决定跳转,而非 EXE
可以把 taken branch penalty 减到 1;需要 bypass to decode stage

但它只 assume simple comparison,对于类似 branch if $1 > $2 这种操作行不通;这种情况需要一条多余的指令处理